

Last week we hosted a free Advanced Kubeflow and MLOps workshop presented by Kubeflow Community Product manager Josh Bottum. In this blog post we’ll recap some highlights from the workshop, plus give a summary of the Q&A. Ok, let’s dig in.
First, thanks for voting for your favorite charity!

With the unprecedented circumstances facing our global community, Arrikto is looking for even more ways to contribute. With this in mind, we thought that in lieu of swag we could give workshop attendees the opportunity to vote for their favorite charity and help guide our monthly donation to charitable causes. The charity that won this workshop’s voting was Doctors Without Borders. They are an international humanitarian medical non-governmental organization of French origin best known for its projects in conflict zones and in countries affected by endemic diseases.. We are pleased to be making a donation of $250 to them on behalf of the Kubeflow community. Again, thanks to all of you who attended and voted!
What topics were covered in the workshop?
- How to install Kubeflow via MiniKF locally or on a public cloud
- Take a snapshot of your notebook
- Clone the snapshot to recreate the exact same environment
- Create a pipeline starting from a Jupyter notebook
- Go back in time using Rok. Reproduce a step of the pipeline and view it from inside your notebook
- Create an HP Tuning (Katib) experiment starting from your notebook
- Serve a model from inside your notebook by creating a KFServing server
- An overview of what’s new in Kubeflow 1.4
What did I miss?
Here’s a short teaser from the 45 minute workshop where Josh walks us through a Kubeflow Pipeline execution graph with extra emphasis on how to create and work with data and artifact snapshots at every step.
Install MiniKF
In the workshop Josh discussed how MiniKF is the easiest way to get started with Kubeflow on the platform of your choice (AWS or GCP). He also talked about the basic mechanics of installing MiniKF.
Here’s the links:
Hands-on Tutorials
Although during the worksop, Josh focused primarily on the examples shown in tutorial #3 (which makes heavy use of Kaggle’s Open Vaccine Covid-19 example), we highly recommend to also try out tutorial #4 which does a great job of walking you through all the steps you’ll need to master, when bringing together all the Kubeflow components to turn your models into pipelines. You can get started with these hands-on, practical tutorials by following these links:
- Tutorial 1: An End-to-End ML Workflow: From Notebook to Kubeflow Pipelines with MiniKF & Kale
- Tutorial 2: Build An End-to-End ML Workflow: From Notebook to HP Tuning to Kubeflow Pipelines with Kale
- Tutorial 3: Build an ML pipeline with hyperparameter tuning and serve the model starting from a notebook
- Tutorial 4: Build an AutoML workflow starting from a notebook
- Tutorial 5: Distributed Training on Kubernetes with Kubeflow, Kale and PyTorch
Need help?
Join the Kubeflow Community on Slack and make sure to add the #minikf channel to your workspace. The #minikf channel is your best resource for immediate technical assistance regarding all things MiniKF!
Missed the Jan 20 workshop?
If you were unable to join us last week but would still like to attend a workshop in the future, register for one of these upcoming workshops.
- Feb 9: Notebooks & Pipelines: Kaggle’s Titanic Disaster Machine Learning Example
- Feb 23: Notebooks & Pipelines: Udacity’s Dog Breed Classification Computer Vision Example
- Mar 9: Notebooks & Pipelines: Kaggle’s OpenVaccine Machine Learning Example
- Mar 23: Notebooks & Pipelines: Kaggle’s OpenVaccine Machine Learning Example
- Mar 10 – Asia Time Zone friendly Advanced Kubeflow Workshop
- Feb 24 – US Time Zone friendly Advanced Kubeflow Workshop
Links to Resources
For those that attended the workshop, here’s the resource links you need to replicate the exercises:
- Kubeflow Community Resources all in one place
- Install MiniKF
- Kubeflow Tutorials
- Find and join a local Kubeflow Meetup
- Upcoming training and certification preparation courses
Q&A from the workshop
Below is a summary of some of the questions that popped into the Q&A box during the workshop. [Edited for readability and brevity.]
How does data transfer happen between Pipeline steps? Do you read/write to intermediate storage?
At Arrikto we take care of this with Rok, a next-generation data management layer, built to solve exactly these types of problems. Rok is included in our EKF offering and can be evaluated for free in MiniKF. Rok is a native Kubernetes storage class which handles the versioning of data, packaging and shipping it across nodes and clusters, focusing on high I/O performance. In regards to Kubeflow, a data scientist only needs to read/write local files. With Rok’s integration with Kale and Kubeflow Pipelines, we make sure that the necessary data will be present at all the pipeline steps that need to consume it.
Does MiniKF support GPUs on a local deployment using Vagrant?
MiniKF when installed on Vagrant doesn’t come with GPU support out of the box. It can be done, but requires a rather complex passthrough workaround. If you want to test GPU support in Kubeflow using MiniKF, we highly recommend deploying on GCP or AWS where this functionality is baked in.
When a Pipeline step is created – lets say the training step, can I assign more resources or perform parallelization only for that processing-intensive step?
Yes. You can specify a specific step to be run with GPUs via the Kale GUI, or other specific resources via Kale’s SDK. We are working on exposing the latter in the GUI as well. Stay tuned!
Can you demonstrate how a distributed training job can be deployed in Kubeflow?
Yes, check out this PyTorch tutorial which walks you through step-by-step how to set up a distributed training job in Kubeflow.
Is the Covid-19 Notebook being used in the workshop available as open source?
Yes. You can check out the JupyterLab Notebook and data set on GitHub.
What’s the difference between MiniKF and Kubeflow running on MicroK8s? Are they the same thing?
No. MiniKF is a packaged Kubeflow distribution, which includes both the Kale and Rok components. It runs on Kubernetes hosted on a single VM, available in both the AWS and GCP marketplaces. MiniKF is supported and maintained by Arrikto. Kubeflow running on MicrosK8s is an add-on that can be enabled after you’ve installed and configured MicroK8s locally. It is assumed that you’ll be able to support the deployment on your own.
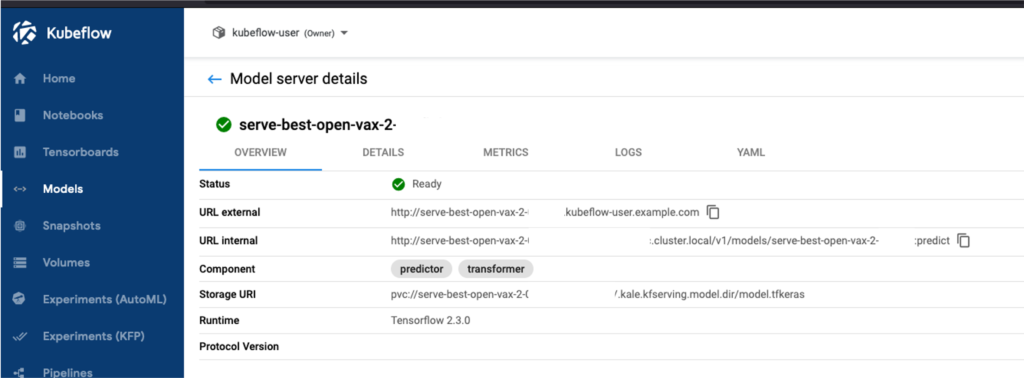
What is the process for exposing my models via link or REST API?
In the demo, Josh showed how in the “Models” tab you could find the live REST endpoints that do inference. We are using Kubeflow’s KFServing component to do that under the hood.
Where can I access the playbacks for previous workshops?
You can find workshop playbacks on our Youtube channel. You can also catch any workshop you missed by checking out our upcoming workshops page.
What’s Next?
- Join the Kubeflow community on Slack and take a moment to introduce yourself!
- Quickly get Kubeflow up and running by getting started with MiniKF
- Contact us to schedule a private Kubeflow and MiniKF workshop for your team.