Last week we hosted the June 2022 “Data Science, Machine Learning and Kubeflow” Meetup. In this blog post we’ll recap some highlights from the Meetup, give a summary of the Q&A and preview what’s next. Ok, let’s dig in.
Join a Meetup near you
First, if you missed last week’s Meetup? No need to suffer from FOMO. Here’s a list of the Meetups that are part of the “Data Science, Machine Learning and Kubeflow” Meetup network. Please join the one that is the most time friendly to your location.
Get involved in the Kubeflow community
- Join Kubeflow Community Slack
- Are you interested in speaking at a future Meetup?
- Is your company interested in sponsoring a Meetup?
- Would you like to be a co-organizer of a local Meetup?
If you answered yes to any of the above, Send one of the organizers/hosts a message on Meetup.com.
Thanks for voting for your favorite charity!

With the unprecedented circumstances facing our global community, Arrikto is looking for even more ways to contribute. With this in mind, we thought that in lieu of swag we could give Meetup attendees the opportunity to vote for their favorite charity and help guide our monthly donation to charitable causes. The charity that won this workshop’s voting was Every Mother Counts (EMC). The Every Mother Counts is a non-profit organization dedicated to making pregnancy and childbirth safe for every mother. They inform, engage, and mobilize new audiences to take actions and raise funds that support maternal health programs around the world. We are pleased to be making a donation of $100 to them on behalf of the Kubeflow community. Again, thanks to all of you who attended and voted!
Talk: Running Kaggle’s Titanic Disaster Machine Learning Example with Kubeflow
Meetup Organizer, Jimmy Guerrero, presented a short workshop using Kaggle’s Titanic Disaster competition.
https://www.kaggle.com/c/titanic
This workshop is for individuals already familiar with machine learning, but new to Kubeflow.
We covered the following topics:
- Overview of Kubeflow
- Installing Kubeflow
- About the Titanic Disaster Example
- Deploying a Notebook Server
- Getting the Titanic Disaster Example Up and Running
- Exploring the Notebook
- Deploying and Running a Pipeline
- Examining the Results
Lightning Talks
There was also one short lightning talk at the Meetup worth checking out.
- A 10 Minute Introduction to Kubeflow: Basics, Architecture & Components – Jimmy Guerrero, VP Developer Relations (Arrikto)
Upcoming July 2022 Meetup
Details about the talks are coming soon! Sign up for the July 7 Meetup here.
Ready to get started with Kubeflow?
Arrikto’s Kubeflow as a Service is the easiest way to get deployed and have a pipeline running in under 5 minutes. Comes with a 14-day free trial with no credit card required. Click to get started.
FREE Kubeflow courses and certifications
We are excited to announce the first of several free instructor-led and on-demand Kubeflow courses! The “Introduction to Kubeflow” series of courses will start with the fundamentals, then go on to deeper dives of various Kubeflow components. Each course will be delivered over Zoom with the opportunity to earn a certificate upon successful completion of an exam. Visit us to learn more.
We hope to see you at a future Meetup!
Q&A from the Meetup
Below is a summary of some of the questions that popped into the Q&A box during the course. [Edited for readability and brevity.]
How do we load a JupyterLab .jpynb file into a Kubeflow Notebook Server?
This short one minute video shows you how.
How can we utilize GPUs for model training?
You’ll want to specify the availability of GPUs when you create your Notebook Server.
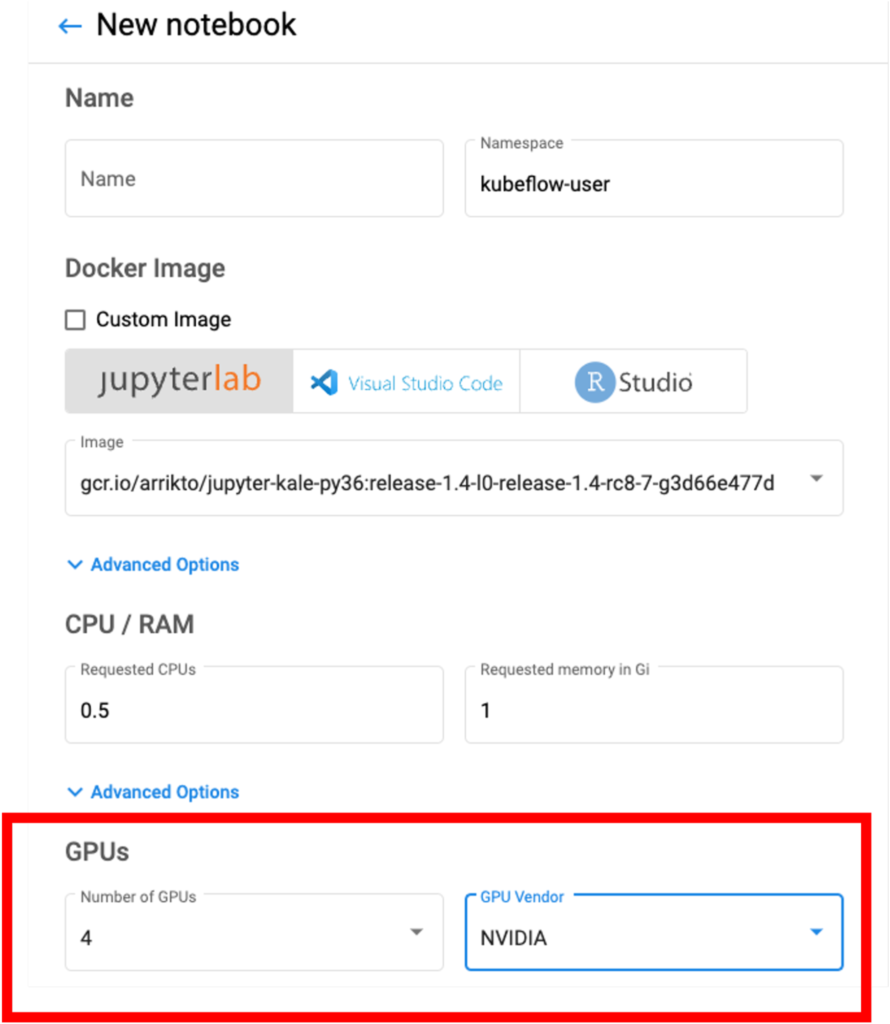
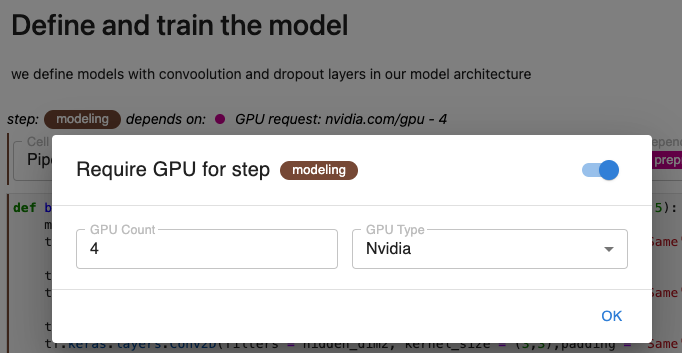
And, if you are using the open source Kale JupyterLab extension, just specify GPUs using a cell annotation. For example:
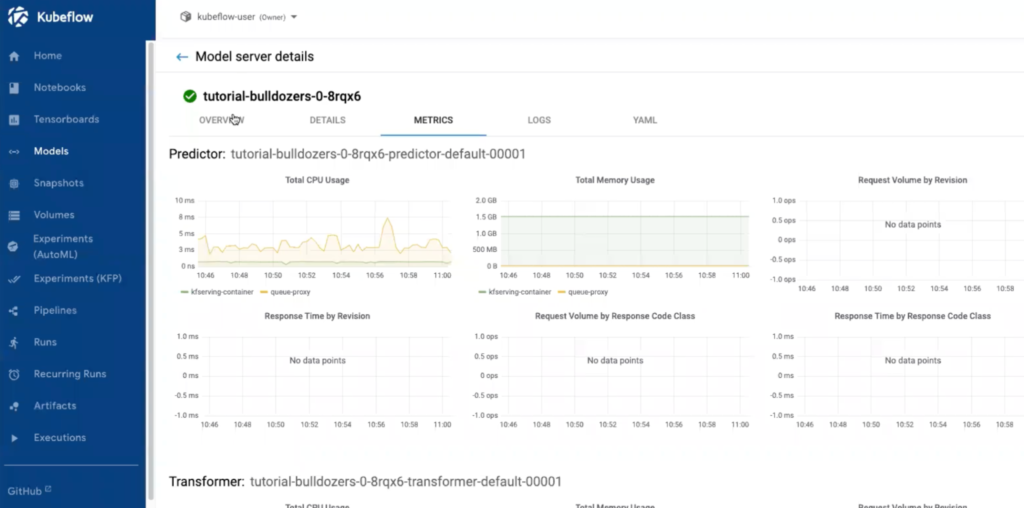
Can Kubelfow serve endpoints for models?
Yes, underneath the covers Kubeflow utilizes KFServing/KServe to serve models. In the Models view of the Kubeflow UI you can view details, metrics, logs and the associated YAML.