

Over the weekend, I was (binge) watching Star Trek: Deep Space Nine. And when I say, “Over the weekend”, I of course mean, “for the last several years” since I am a bit of a Star Trek Nerd. Time and again I noticed, the most irritating thing about Deep Space Nine is the conspicuous lack of the USS Enterprise, the flagship of the United Federation of Planets, during the Dominion War.
A few fan fiction writers have attempted to bridge this gap; you can see a fully curated list of all the Enterprise’s (mis)adventures here. But fan-fiction always reads like Star Trek Voyager to me, that is to say: it’s unbearable- just kidding, most fan fiction isn’t as bad as Voyager, but it’s also not canon.
But I digress- I wanted to know what the USS Enterprise and her crew were probably up to during the Dominion war. I don’t need canon- but I also don’t want to wade through the fan-fiction swamps.
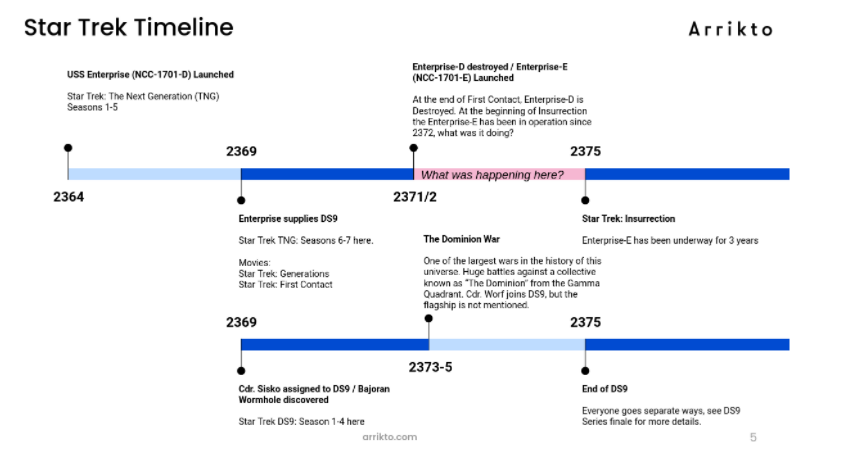
Visual representation of the problem we are facing.
So since I am only interested in what they were probably doing, I figured probabilistic inference would be my go to set of algorithms- but I saw this post on dev.to, and I got to thinking- who am I to think I know what sorts of zany adventures the Enterprise got up to. Oh, probabilistic inference might tell me what squadron the Enterprise was in in a particular battle, but really stories are about interpersonal relationships, and how the relationships among the crew developed, and how they interacted with the inhabitants of DS9, are all of which are most certainly unknown unknowns.
So based on a header image of an article I never read, I will use Deep Learning to discover the fate of the Enterprise during the Dominion War.
My first stop on this journey was to check out a toy I made back in like 2015 I think- the Star Trek Chat Bots. So I went, and I asked- “Where was the USS Enterprise doing during the Battle of Betazed?” As the bots are won to do, they just babbled on in a mildly amusing sort of way, but gave no answers. You see, that’s all they can do.
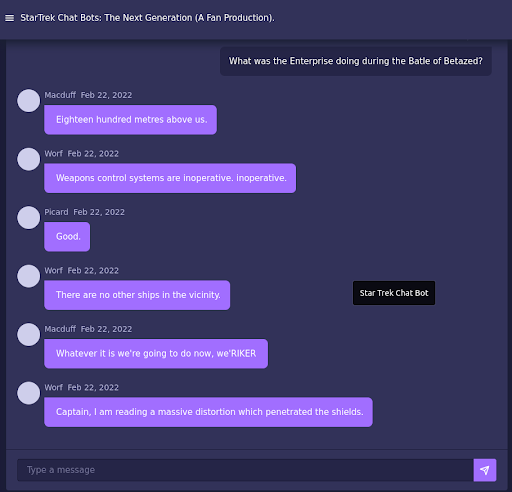
Src: startrekbots.com/
You see the algorithm that powers the Star Trek Chat Bots is Neural Machine Translation, which was developed for translating sequences of characters from one language to another. My clever trick was to dice up Star Trek screen plays and use some word vectors such that any 100 words of screen play would predict the next 15 words.
It worked well. In 2018, I made a Twitter interface and a few bots, over the years I made a few attempts at React UIs as well and the current edition of StarTrekBots.com was me learning on React and Firebase. You can also see the original site (my first attempt at React) on an S3 Bucket here.
Fun as they have been as a platform for learning, they are just trying to guess at the next line- they are to storytellers, what bad improv actors are to improv: They can make some funny one liners, but plot is hard.
But that was then and this is The Next Generation– by which I mean: my job is to do fun things with company supplied compute resources and then blog about it- sound like a fun job? Join me, we’re hiring.
I digress, I have time and resources to play now. You may recall a bunch of hype about AI dooming us all from those writers of their own press releases at OpenAI. Spoiler: For all the hype of Open AI- trying to get it to respond or talk about what you want is like asking a three year old their favorite color: It will babble on for a while- if it answers your question it will only be by chance, and the novelty wears off quickly, which is also my impression of three year olds.
But credit where it’s due- it does craft a better story than a translation algorithm. My short blurb about GPT2 is that it is about 4 generations more modern in a field that has advanced at a dizzying pace through the 2010s.
There were lots of important advances in technology during the 2010s such as deep learning, natural language generation, and the ability to detect cats in photos. But also there were big developments in making that technology more accessible to end users. Enter huggingface.
Huggingface is … apparently a company? I was just looking around their website for a bit of history on the project, which I honestly thought was community driven open source, but it seems like it’s not. It is however a library of NLX (that’s a new acronym I made up for natural language process (NLP), natural language generation (NLG), or any other type of natural language whatever) models, such as BERT, T5, GPT/2, and others. It provides some convenience wrappers around PyTorch and Tensorflow, and most importantly for my purposes make it much much simpler to finetune language models (such as GPT2).
But where does one get plot summaries from these two hallmarks of western literature? Wikipedia of course. I accidentally deleted the script, but let me walk through the highlights:
- Get the list of episodes page to build a list of links to each episode.
- Iterate through the episode pages collecting the paragraphs in the “plot” section.
- Complications: Wikipedia is a mess of drive by commits, and sometimes the section is labeled “Plot” sometimes “Plot Summary”, sometimes its a two-parter and each part has a separate page, sometimes its “Part 1 Summary” and “Part 2 Summary”. 90% of that linked code was just dealing with all of those ‘gotchyas’. Its a pretty simple webscraping exercise to recreate- it shouldn’t take you longer than two episodes of DS9 to work it out.
For fine tuning a huggingface model, I mainly read/ copy-pasted from this notebook. I say that because the intricacies of fine tuning an algorithm are external to this post- there are other resources, which explain the process in more detail. But it is a shockingly easy thing to do.
The key thing I will note, if you’re doing this on Kubeflow you need to do the finetuning in a pipeline. You can check the code runs in a notebook cell, but you’re going to want to use GPUs and other things that the notebook server won’t (shouldn’t) have.
So I fine tuned the algorithm. And gave it a prompt of: “During the Battle of Betazed, the USS Enterprise”, and got the following results:
Act 1: During the Battle of Betazed, the USS Enterprise drops a fragment of war debris (including the first communication ever sent on a Cardassian vessel) and makes a direct landing in the Neutral Zone. The crew is able to free the ship, using photon torpedoes. When the Enterprise lands, it sends a distress call to the Gamma Quadrant, reporting the distress of a nearby colony. However, the colony itself is unaware of the distress call, and the Enterprise cannot approach the probe. While returning from a medical mission, the crew suffers a hull breach from the Enterprise, destroying many life forms. In a moment, the colony's leader, Kajada Kajada (Armin Shimerman), appears and explains herself to be the true leader of the entire Enterprise crew. She offers the Enterprise a chance to leave once the war is over, but Captain Jean-Luc Picard (Patrick Stewart) refuses and instead attempts to lead it.
Act 2: During their final destination, the Enterprise tows a survivor pod from the crashed ship and brings it
back to the Enterprise. However, it is immediately damaged by the explosion and the transport vessel is no
closer to arriving. At the same time, the ship is struck by the explosion, injuring Dr. Crusher, who is trapped
on the ship. The transport vessel is trapped within the rock. The survivor pod is sent to Earth and the
two-dimensional creatures are rescued. While the Enterprise is transported to Earth, a small rift begins to
appear near their ship, and Lt. Data (Brent Spiner) determines the crew is trapped, and attempts to warn them
that they cannot leave until they have determined what is really going on. The Enterprise is attacked by four
aliens, each of whom has joined the ship and was previously a part of a previous mission when the ship crashed
into a harsh, unidentified debris field. Data determines that all the aliens were part of a single alien lifeform,
the first alien encountered at a different time. The Enterprise crew tries to send the message to the aliens that
they are crew members of a larger crew, but they find the ship has fired on them, straining the hull to solidify
the debris, causing the Enterprise to move out of phase with them. In order to avoid collision with the Enterprise,
they modify a thruster to move the Enterprise backwards, though the thruster's sweep forces the Enterprise back
into phase, with the two creatures trapped inside the rock. The creatures fire upon the Enterprise, and then
attack the crew with torpedoes.
Act 3: The survivor pod is then beamed to the Enterprise, where Dr. Crusher is sent to investigate, having
recovered the ship's last communication from the crew. The ship is contacted by a survivor pod, who informs
Data of her late wife's death. He explains that her last memory was of the ship's first officer, and that her
family is very close, but that everyone else was too afraid to talk to her and suffered as a result of her
husband's death. She tells her story to help him find the reason behind her disappearance. He sends her back to
the Enterprise, where she meets with the senior staff, explaining that he and his girlfriend, Lauren G. Taylor,
are all humans, and they have all had common experiences in life; however, her experiences were short-term and
were likely to pass before they were apart, and the crew is afraid to say goodbye to those close to her. At the
ready, Lwaxana reports to the senior staff, prompting them to transport them safely back to the Enterprise,
where Lwaxana is informed that Lwaxana's parents, Thomas and Lore (named later in the episode), are both dead
and live. Lwaxana explains that her parents are "the same people" but were not killed in the same accident.
The senior staff debate terminating the relationship, but Lwaxana's parents, Lore and Tumak (seen for their
first time), decide that it is best for Lwaxana to tell the truth, even though both are very afraid to say
goodbye to those close to her. A distraught Lwaxana asks the senior staff to discuss their current predicament,
and the staff agrees to discuss the issue.
Which in all fairness is a good example of some of the issues with GPT2. A lot of pronoun references to vague (or non existent) (or gender non-agreeing) targets. But you do get a bit of a story- and there is usually some goofball thing in the story that is good for a chuckle.
You can get different results based on:
- Random seed of the trained model- that is to say, your model will come up with something different from mine.
- The input, whether you use a comma, trailing space, or other differences in the string.
- Adjusting the parameters in the generator.
Which brings me to my next section on serving, and how to interact with my cut of this algorithm.
When I make this into a tutorial or for almost any other use case- the right way to serve this model would be with KServing. But in my use case, I just want to post it somewhere free forever with low usage, so I went with my old stand by, Apache Openwhisk-incubating. My reason was I want folks to be able to play with the final toy, but I don’t want to pay for hosting because I’m a cheapskate.
Apache Openwhisk-incubating is an open source Functions as a Service (FaaS) platform. Think of it as an open source version of AWS Lambda, or GCP/Azure’s Cloud Function offering. It actually is the FaaS offering at both IBMCloud and Adobe Cloud. (My time at IBMCloud was where I learned of/fell in love with Openwhisk.
A full tutorial on making Openwhisk functions is out of scope for this blog post, but the steps are:
- Tarball the output model from the finetuning and download it.
- Make a docker based on one of the other Openwhisk images
- Add the model to the Docker image
- Made a reader function that takes a an input string in a dictionary as a parameter and returns the output string (also in a dictionary).
There is a philosophical question in English, commonly misattributed to George Berkely, “If a tree falls in the forest, but no one hears it- did it make a sound?”
Let me update that to something more relevant to the early 21st century. “If you make a cool AI algorithm, but don’t make a WebUI and host it somewhere people can play with, did you even make it?”
To that end, I (poorly) made a React app that hits my Openwhisk endpoints, and lets you play with this thing. The code for the React site is also in the repo but in short I’ll talk about what sort of magic it is doing.
- You put a phrase in- The fine tuned algorithm generates a story based on that phrase, usually multiple sentences long.
- That phrase is returned, but you’ll see a status indicating it is still working. By “still working” it means, it split the sentences and is using each sentence as a phrase seed for more content.
- The final output will be a story in multiple “acts”. Each sentence from step 1 was then blown out into an act in step 2. This is somewhat reflective of the way stories are constructed in real life.
- If you wanted to hack this and make it more meta, you could just seed a phrase that would produce a one paragraph summary of the season, which then would produce episodes, which then would produce acts. If you wanted to get more depth, you could have it take each act and flesh it out into scenes with more detail as well.
But in the meantime, just enjoy the toy, a sort of magic 8-ball of what all might have happened in a non-existent crossover universe. The public url for the toy is https://plots.startrekbots.com/
It wouldn’t take too much work to mash up any long running show- ideas I’ve had are:
- Seinfield and M*A*S*H*
- Futurama and Friends
So here is the outline for a fun way to kill a Sunday afternoon, if you make anything fun shoot me an email and let me know about it-