

Welcome to the fourth blog post in our “Kubeflow Fundamentals” series specifically designed for folks brand new to the Kubelfow project. The aim of the series is to walk you through a detailed introduction of Kubeflow, a deep-dive into the various components, add-ons and how they all come together to deliver a complete MLOps platform.
If you missed the previous installments in “Kubeflow Fundamentals” series, you can find them here:
In this post we’ll focus on getting a little more familiar with Kubeflow external tools and add-ons including Istio, Kale, Rok and a few tools for serving. Ok, let’s dive right in!
Why do we need external add-ons?
As you become more familiar with Kubeflow and how it works, you’ll start to identify workflow goals which Kubeflow can satisfy. You will likely need to integrate additional software to allow Kubeflow to more tightly integrate with your specific environment. These add-ons also make specific tasks easier, more secure, scalable and faster. For example, some popular external add-ons include:
- Istio – Enables end-to-end authentication and access control
- Kale – Enables data scientists to orchestrate end-to-end machine learning workflows
- Rok – Data management for Kubeflow that enables versioning, packaging, and secure sharing across teams and cloud boundaries
- Seldon Core Serving – Enables model serving using Seldon Core with support for multiple frameworks
- NVIDIA Triton Inference Server – Open-source inference serving that supports multiple frameworks
For a complete list of all the add-ons available in the Kubeflow ecosystem, check out the Docs. (Note: unfortunately the official Docs appear to be outdated in some spots so “your mileage may vary” as to the accuracy of the information.)

Istio
While you can run Kubeflow without Istio (as illustrated here and here), it is the recommended solution for managing authentication and access control. As a result Istio is often listed as an add-on despite it being shipped and bundled as a component. For those unfamiliar with the concept of service meshes or Istio specifically, here’s what you need to know:
- Istio is an open source service mesh popular with Kubernetes deployments, but it also supports VMs
- A service mesh is a dedicated infrastructure layer built right into the application itself
- It helps control how different parts of an application share data amongst themselves
- An application has different parts to it, or “services,” which is how we arrive at the term “service mesh.” Istio “meshes” these “services” together!
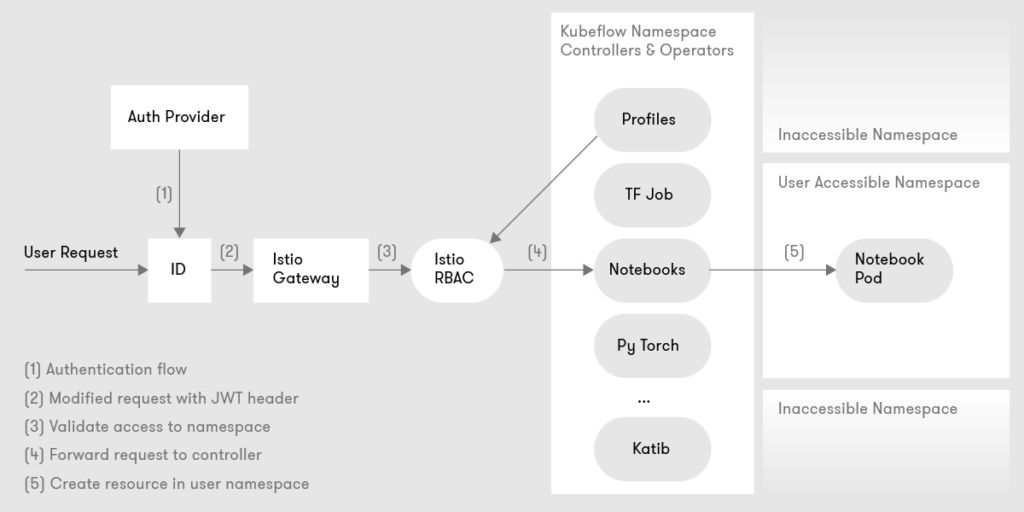
Kubeflow in most cases relies on Istio to provide end-to-end authentication and access control between the different services inside the platform. Istio also serves as a foundational piece of technology to deliver multi-user isolation.

Kale
Kale, which stands for “Kubeflow Automated pipeLines Engine” is an open source project that aims to simplify the deployment of Kubeflow Pipelines workflows. Kale is truly an add-on that you have to enable post-installation, unless you deployed Kubeflow using the MiniKF or Enterprise Kubeflow distributions which pre-bundle and configure it for you.
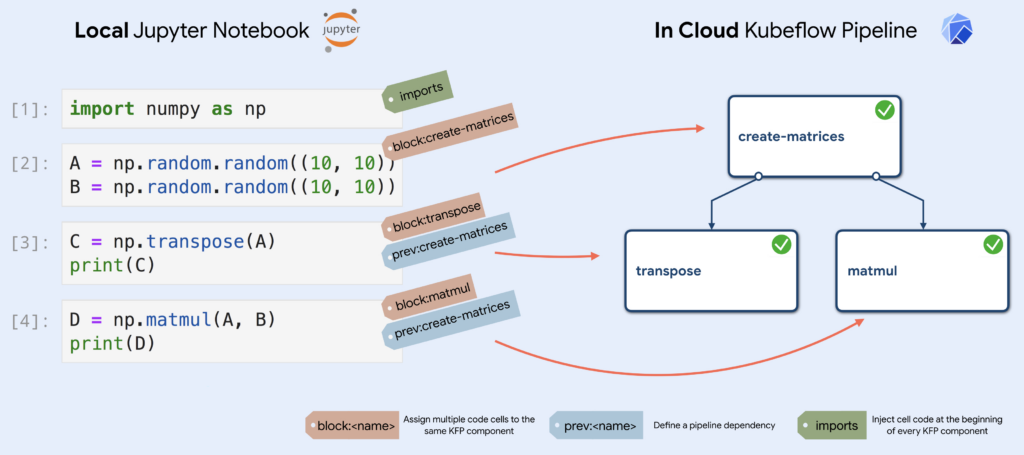
Kale provides a UI in the form of a JupyterLab extension. You can then annotate “cells” within Jupyter Notebooks to define: pipeline steps, hyperparameter tuning, GPU usage, and metrics tracking. Kale enables you to, with the “click a button”:
- Create pipeline components and KFP DSL
- Resolve dependencies
- Inject data objects into each step
- Deploy the data science pipeline
- Serve the best model
As you can imagine, with all these capabilities that Kale offers out of the box, Kale is a very popular Kubeflow add-on that helps users avoid writing a lot of tedious boilerplate. To experience the awesomeness of Kale, we highly-recommend working through a few tutorials:
- An End-to-End ML Workflow: From Notebook to Kubeflow Pipelines with MiniKF & Kale
- Build An End-to-End ML Workflow: From Notebook to HP Tuning to Kubeflow Pipelines with Kale
- Build an ML pipeline with hyperparameter tuning and serve the model starting from a notebook
- Build an AutoML workflow starting from a notebook
If you want to learn more about Kale consider the Kale 101 course from Learn-Kubeflow Repository on Arrikto Academy.

Rok
The Rok data management layer for Kubeflow is a project maintained by Arrikto. Like Kale, the Rok add-on comes pre-bundled in the MiniKF or Enterprise Kubeflow distributions. At a low-level, Rok allows you to run and snapshot the stateful containers over fast, local NVMe storage on-prem or on the cloud. Rok snapshots include the whole application, along with its data and distribute it efficiently.
What does this mean in regards to Kubeflow? With Rok we can automatically snapshot pipeline code and data at every step and restore full environments, volumes and specific execution state. This enables you to restore any pipeline step to its exact execution state for easy debugging. This capability also unlocks collaborative opportunities with other data scientists through a GitOps-style publish/subscribe versioning workflow.
Model Serving in Kubeflow
To understand the subsequent add-ons you need to first understand how model serving works in Kubeflow.
At a high-level, model serving is simply the act of making a machine learning model available for others to use. In practical terms, it means that the models we’ve built with TensorFlow, Pytorch, or another framework, are being ”served” or made available as a web service or API using something like KFServing or SeldonCore.
Kubeflow supports several model serving systems that enable multi-framework model serving. A few of these are going to include KFServing (now known as KServe), Seldon Core Serving and Triton Inference Server.

Seldon Core Serving
Even though the official Kubeflow Docs list Seldon Core Serving as an external add-on, just like Istio it technically ships with Kubelfow. We should also note that the Seldon ML Server ships with the latest v0.7 KServe release. Seldon ML Server is an open source inference server for machine learning models that aims to provide an easy way to start serving your models through a REST and gRPC interface. Seldon ML Server is fully compliant with KFServing’s V2 Dataplane specification as well.
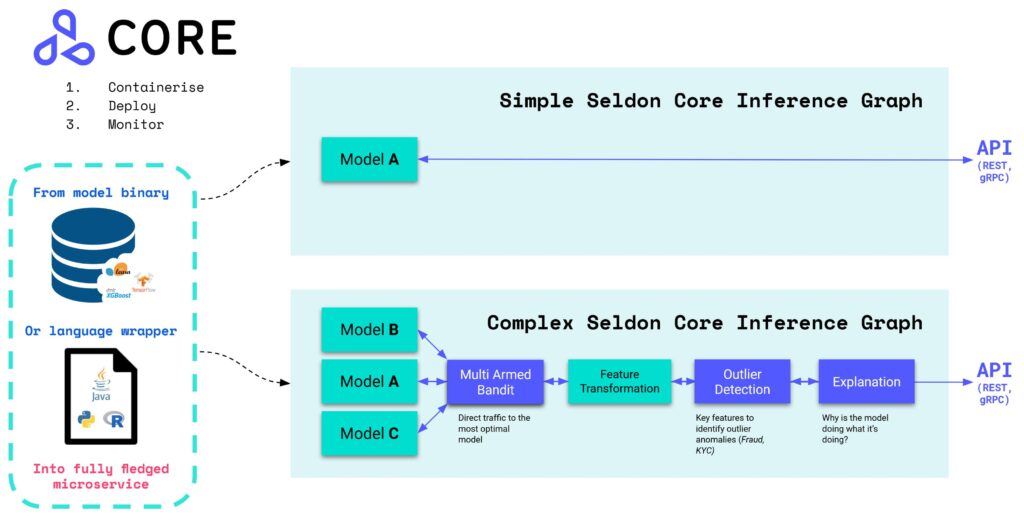
Additional features include:
- Multi-model serving, allowing users to run multiple models within the same process.
- Ability to run inference in parallel for vertical scaling across multiple models using a pool of inference workers.
- Support for adaptive batching, to group inference requests together on the fly.
- Scalable deployment using Kubernetes native frameworks, including Seldon Core and KServe (formerly known as KFServing), where MLServer is the core Python inference server used to serve machine learning models.
- Support for the standard V2 Inference Protocol on both the gRPC and REST flavors, which has been standardised and adopted by various model serving frameworks.

NVIDIA Triton Inference Server
Aside from KServe and Seldon you do also have the option of using the Triton Inference Server maintained by NVIDIA. When using the Triton Inference Server the inference result will be the same as when using the model’s framework directly.
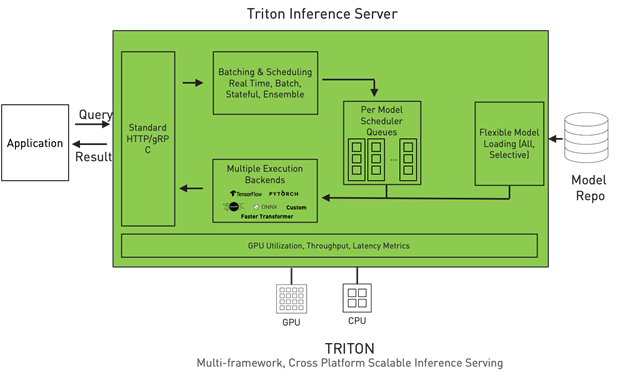
However, with Triton you also get things like:
- Concurrent model execution (the ability to run multiple models at the same time on the same GPU)
- Dynamic batching to get better throughput.
- Replace or upgrade models while Triton and the client application are running.
- Can be deployed as a Docker container, anywhere – on premises and on public clouds.
- Support for multiple frameworks such as TensorRT, TensorFlow, PyTorch, and ONNX on both GPUs and CPUs
What we’ve presented so far is just a sample of the Kubeflow add-ons that are available. Again, for a complete list of all the add-ons check out the Docs.
What’s next? Part 5 – An Introduction to Jupyter Notebooks
Stay tuned for the next blog in this series where we’ll focus on getting a little more familiar with Jupyter notebooks and how we can leverage them within Kubeflow as part of our machine learning workflow.
Book a FREE Kubeflow and MLOps workshop
This FREE virtual workshop is designed with data scientists, machine learning developers, DevOps engineers and infrastructure operators in mind. The workshop covers basic and advanced topics related to Kubeflow, MiniKF, Rok, Katib and KFServing. In the workshop you’ll gain a solid understanding of how these components can work together to help you bring machine learning models to production faster. Click to schedule a workshop for your team.
About Arrikto
At Arrikto, we are active members of the Kubeflow community having made significant contributions to the latest 1.4 release. Our projects/products include:
At Arrikto, we are active members of the Kubeflow community having made significant contributions to the latest 1.4 release. Our projects/products include:
- Kubeflow as a Service is the easiest way to get started with Kubeflow in minutes! It comes with a Free 7-day trial (no credit card required).
- Enterprise Kubeflow (EKF) is a complete machine learning operations platform that simplifies, accelerates, and secures the machine learning model development life cycle with Kubeflow.
- Rok is a data management solution for Kubeflow. Rok’s built-in Kubeflow integration simplifies operations and increases performance, while enabling data versioning, packaging, and secure sharing across teams and cloud boundaries.
- Kale, a workflow tool for Kubeflow, which orchestrates all of Kubeflow’s components seamlessly.