

Welcome to the first in a series of blog posts where we’ll walk you through a detailed introduction to Kubeflow. In this series we’ll explore what Kubeflow is, how it works and how to make it work for you. In this first blog we’ll tackle the fundamentals, and use it as a foundation to introduce more advanced topics. Ok, let’s dive right in!
What is Kubeflow?
Kubeflow as a project got its start over at Google. The idea was to create a simpler way to run TensorFlow jobs on Kubernetes. So, Kubeflow was created as a way to run TensorFlow, based on a pipeline called TensorFlow Extended and then ultimately extended to support multiple architectures and multiple clouds so that it could be used as a framework to run entire machine learning pipelines.
The Kubeflow open source project was formally announced by David Aronchick and Jeremy Lewi at the end of 2017 in the blog post, “Introducing Kubeflow – A Composable, Portable, Scalable ML Stack Built for Kubernetes.”
In a nutshell, Kubeflow is the machine learning toolkit for Kubernetes.
Why Kubeflow?
At the time of Kubeflow’s announcement, there were two big IT trends that were beginning to pick up steam – the mainstreaming of cloud-native architectures, plus the widespread investment in data science and machine learning.

As a result, Kubeflow was perfectly positioned at the convergence of these two trends. It was cloud-native by design and was specifically designed for machine learning use cases. Since 2017, it should be readily apparent to even the most casual observer of IT trends, that Kubernetes and machine learning have only increased in popularity and have shown to be an obvious technological pairing.
What challenges does Kubeflow aim to solve?
The charter of the Kubeflow project continues to be, “To make deployments of machine learning workflows on Kubernetes simple, portable and scalable, by providing a straightforward way to deploy best-of-breed open-source systems for machine learning to diverse infrastructures.” With the added benefit that wherever you can run Kubernetes, you can run Kubeflow!
Every organization that is actively deploying machine learning workloads (or attempting to!), knows that there are a lot of problems that need to be solved along the way. Kubeflow aims to be the technology that can solve these problems for both Data Scientists and operations teams. Challenges like:
- Data loading
- Verification
- Splitting
- Processing
- Feature engineering
- Model training
- Model verification
- Hyperparameter tuning
- Model serving
- Security and compliance
- Data management
- Reproducibility
- Observation and monitoring
You can learn more about why these challenges can be difficult for some organizations to overcome by reading the blog post titled, “Why 90% of machine learning models never hit the market”, by Rhea Moutafis. Spoiler alert, it isn’t always the software’s fault!
Getting familiar with Kubeflow components
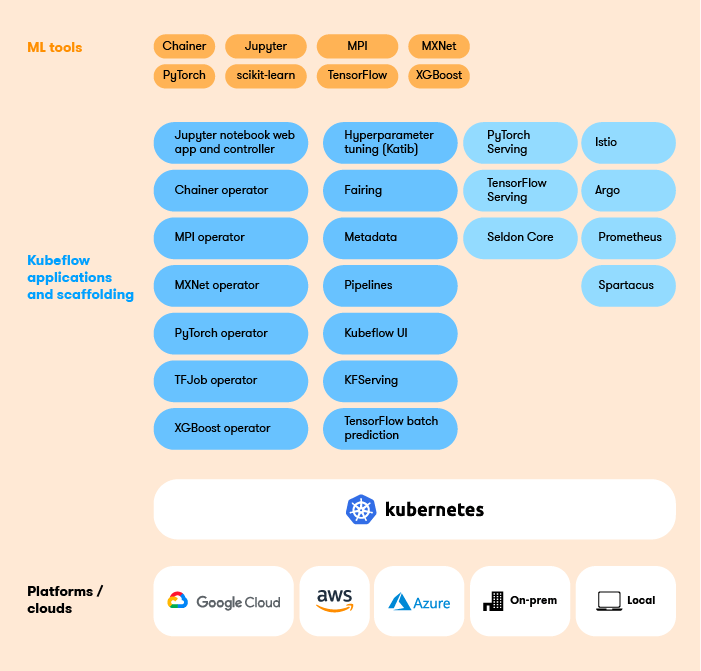
There are seven core components that make up Kubeflow. Let’s do a quick overview of each one and the role it plays. (Don’t worry, in upcoming posts we’ll dive into each one of these components!)
Central Dashboard
The central user interface (UI) in Kubeflow. Within the dashboard you can access a variety of components including Pipelines, Notebooks, Katib, Artifact Store and manage contributors.
Notebook Servers
Jupyter notebooks work well in Kubeflow because they can easily integrate with the typical authentication and access control mechanisms you may find in an enterprise. With security sorted out, users can then confidently create notebook pods/servers directly in the Kubeflow cluster using images provided by the admins, and easily submit single node or distributed training jobs, vs having to get everything configured on their laptop.
Kubeflow Pipelines
Kubeflow Pipelines is used for building and deploying portable, scalable machine learning workflows based on Docker containers. It consists of a UI for managing training experiments, jobs, and runs, plus an engine for scheduling multi-step ML workflows. There are also two SDKs, one that allows you to define and manipulate pipelines, while the other offers an alternative way for Notebooks to interact with the system.
KFServing
KFServing provides a Kubernetes Custom Resource Definition for serving machine learning models on a variety of frameworks including TensorFlow, XGBoost, scikit-learn, PyTorch, and ONNX. Aside from providing a CRD, it also helps encapsulate many of the complex challenges that come with autoscaling, networking, health checking, and server configuration.
We should note that the KFserving component is currently in Beta.
Katib
Katib (which means “secretary” in Arabic) provides automated machine learning (AutoML) in Kubeflow. Like Kfserving, Katib is agnostic to machine learning frameworks. It can perform hyperparameter tuning, early stopping and neural architecture search written in a variety of languages.
Also, similar to KFServing, Katib is also currently in Beta.
Training Operators
In Kubeflow you train machine learning models with operators. There are currently five operators that are supported. They include:
- TensorFlow training via tf-operator
- PyTorch training via pytorch-operator
- MPI training via mpi-operator
- MXNet training via mxnet-operator
Multi-Tenancy
In a typical machine learning production environment, the same pool of (expensive) resources will need to be shared across different teams and individual users. As such, administrators will need a mechanism for isolating users and their resources so they don’t view or change the resource allocations of others. Fortunately, with the latest Kubeflow v1.3 release there is now support for multi-user isolation so users “only see what they should see” and cannot modify the resources of other users.
Kubeflow interfaces
In Kubeflow there are a variety of interfaces that you can interact with. The first is the UI (which we already covered), the balance is an assortment of APIs and SDKs that you interact with programmatically. They include:
- Kubeflow Metadata API and SDK
- PyTorchJob Custom Resource Definition
- TFJob Custom Resource Definition
- Kubeflow Pipelines API and SDK
- A Kubeflow Pipelines domain-specific language (DSL)
- Kubeflow Fairing SDK
Kubeflow as a Machine Learning workflow
Stay tuned for the next blog in this series where we’ll explore what a typical machine learning workflow looks like and how specific Kubeflow components fit into the workflow. We’ll also cover what choices are available in regards to distributions and installation options.
Book a FREE Kubeflow and MLOps workshop
This FREE virtual workshop is designed with data scientists, machine learning developers, DevOps engineers and infrastructure operators in mind. The workshop covers basic and advanced topics related to Kubeflow, MiniKF, Rok, Katib and KFServing. In the workshop you’ll gain a solid understanding of how these components can work together to help you bring machine learning models to production faster. Click to schedule a workshop for your team.
About Arrikto
At Arrikto, we are active members of the Kubeflow community having made significant contributions to the latest 1.4 release. Our projects/products include:
- Kubeflow as a Service is the easiest way to get started with Kubeflow in minutes! It comes with a Free 7-day trial (no credit card required).
- Enterprise Kubeflow (EKF) is a complete machine learning operations platform that simplifies, accelerates, and secures the machine learning model development life cycle with Kubeflow.
- Rok is a data management solution for Kubeflow. Rok’s built-in Kubeflow integration simplifies operations and increases performance, while enabling data versioning, packaging, and secure sharing across teams and cloud boundaries.
- Kale, a workflow tool for Kubeflow, which orchestrates all of Kubeflow’s components seamlessly.