

In part 1 of this series on Data as Code we discussed how software development practices have changed dramatically, yet the other half of the equation, data, hasn’t kept up.
In part 2 we showed how Data as Code brings balance to the DevOps equation for a real-world scenario enabling a full CI/CD pipeline of automated machine learning across wearable devices, near edge, and the public cloud.
In this final discussion, we will examine how the benefits of Data as Code enable significant productivity enhancements and cost savings for data scientists and machine learning engineers as they develop, train, test, and deploy their models.
Accelerate Code and Model Development While Reducing Wait Time and Costs
One of the most time consuming and error-prone challenges when developing and testing new machine learning models, and for software development in general, is building and configuring a repeatable and scalable process to test against known good data.
Advanced organizations take this a step further and automate the orchestration of their testing process to skip tests that are known to pass and inject the appropriate testing data set at the right time so you can accelerate your testing with minimal unnecessary rework.
When you adopt a Data as Code approach, especially when powered by Arrikto’s data management platform, what was once a significant engineering challenge becomes a few trivial lines in your testing apparatus.
Additionally, because we recommend using local NVMe attached disks, your testing and training not only completes orders of magnitude more quickly, but you slash your storage and compute costs because you now no longer require expensive network-attached storage or long-running compute instances.
Accelerating Code and Model Development for an Individual Data Scientist
Let’s see how this works for an individual data scientist working alone.
The Arrikto Data as Code approach not only enables us to manage and process data in the same way and with similar methodologies as we do for code, but integrates this functionality directly into the application layer.
Storage administrators and infrastructure engineers operate at the infrastructure layer. developers and data scientists do not have the expertise, nor the desire, to do so. They want to focus on their job – writing code and developing machine learning models to advance business goals.
So why would we expect a data scientist to manage storage and lower level infrastructure components? Seems silly, but that is exactly what we expect today.
Rather, let us take an application-centric approach that integrates with not only the workflows and processes but the applications data scientists use.
When a data scientist is developing their model code, they organize it into clear sections for data prep, load, analysis, transform, etc…
Typically, as data scientists test and train their models, each test is a complete run. This incurs a significant cost for storage and compute resources, but also takes an extraordinary amount of time.
By applying the Arrikto implementation of Data as Code, a data scientist can simply annotate their model code tagging each cell within a Jupyter Notebook, and then set pipeline dependencies. This greatly simplifies and accelerates testing and training.

This automatically generates thin snapshots, almost instantly, to allow for each phase of testing and training to focus on the new or modified sections without having to waste time, resources, and budget on previously testing and working code.
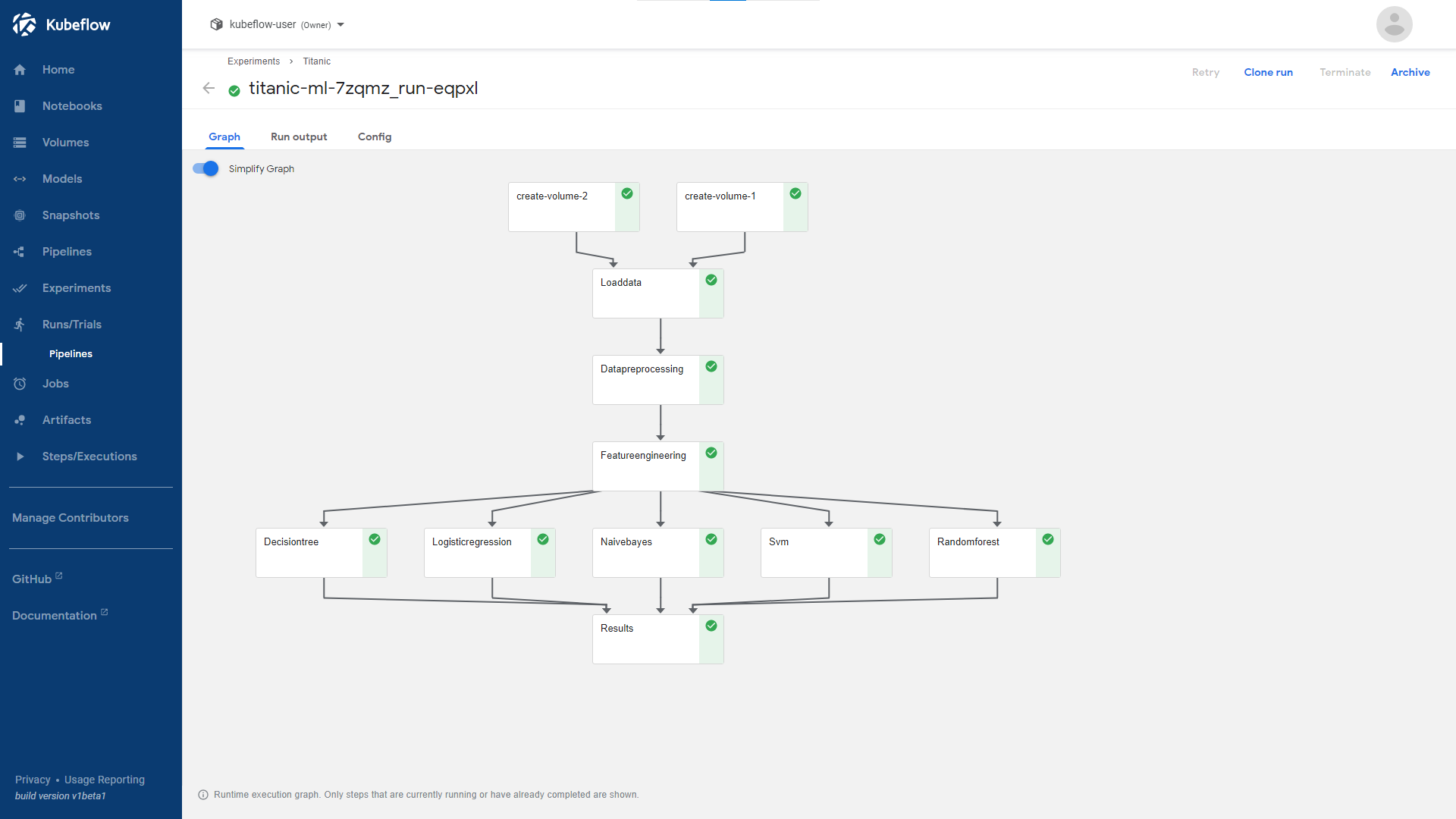
pipeline graph
Pipeline graph
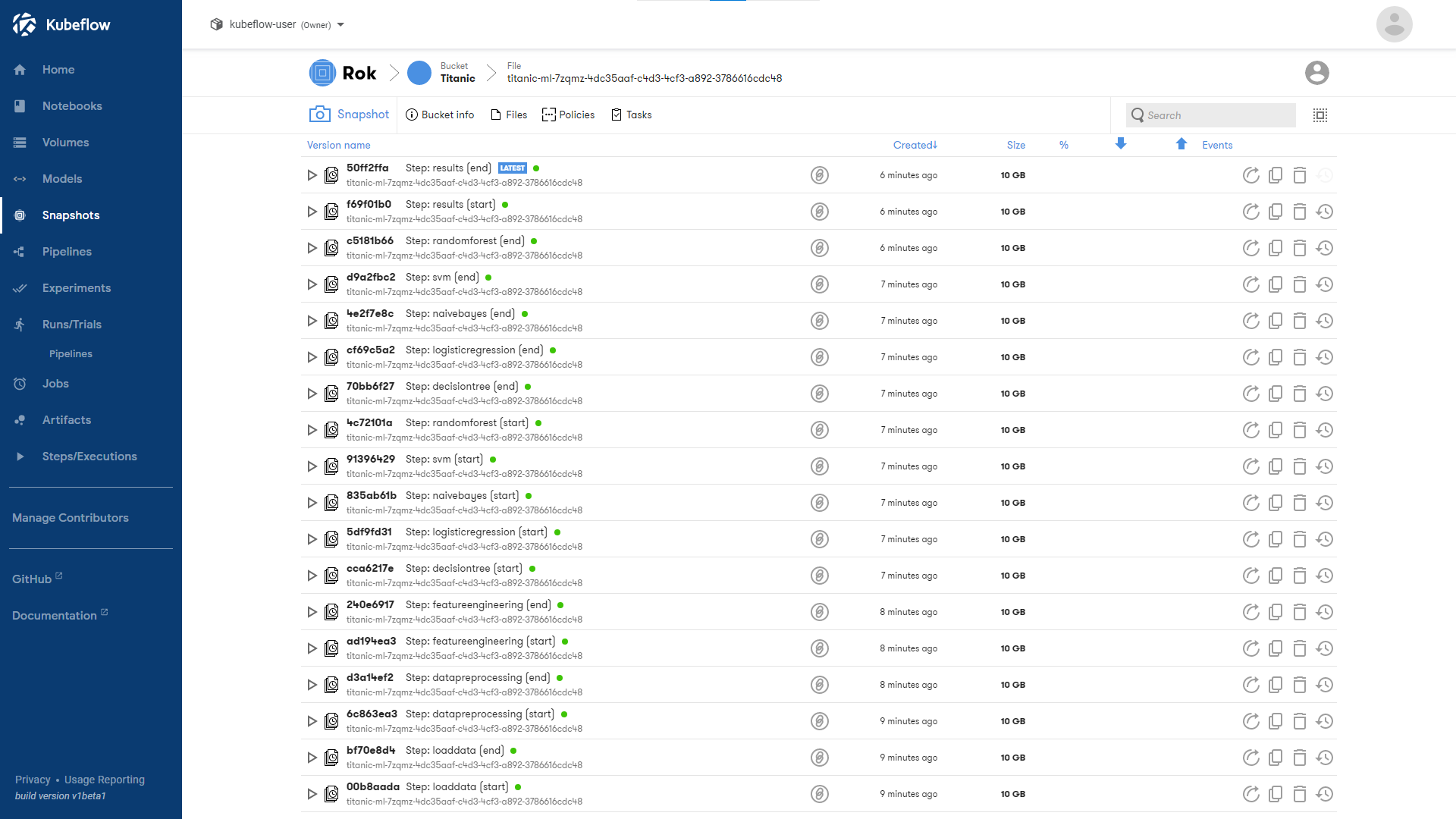
pipeline-snapshots
Snapshots of every pipeline step
Here you can see the application of this principle at an even larger scale. To tune models for optimal performance, a process known as hyperparameter optimization (HPO) takes place that performs a matrix of tests with all parameter variations until the model’s goal is met.
This is a labor, time, and resource intensive process that can easily take days or even weeks. One of our clients reported that they were never able to fully complete this stage as it took almost two months and was deemed overly expensive without meeting their internal ROI metrics.
By building upon the simple model code annotations introduced above, you are able to automate and rapidly test many thousands of variations with the minimum required cloud compute and storage resources, time, and most importantly cost. This is because we can cache each step and rapidly reuse repeated steps.
This alone has proven to accelerate data scientist productivity from weeks to days and slash their cloud storage and compute costs to a fraction of their previous bill.
Scaling Accelerated Code and Model Development For An Entire Team With Collaboration
Small organizations may only have a single data scientist, but large enterprises often have teams that need to collaborate and work effectively.
In the section above, we saw how Arrikto applies Data as Code to help an individual data scientist. Now we will highlight how to scale this across an entire team of data scientists. You can even take this approach and use it to enable collaboration across your organization or even with your customers and suppliers.
We are familiar with the concept of checking our code in and out of a shared repository, and creating and merging branches for feature development and bug fixes.
With Data as Code, Arrikto enables the same process for your data.
More significantly, we enable data mobility and synchronization as well.
As we saw above, each step in a pipeline can be automatically snapshotted. When working in teams, we can not only share these snapshots with our colleagues but keep them in sync for rapid development.
If we think of data simply as buckets, and each data set a file, then each snapshot is simply a revision. Code revision tools such as git take a similar approach.
User Accessible Detailed Snapshot Data
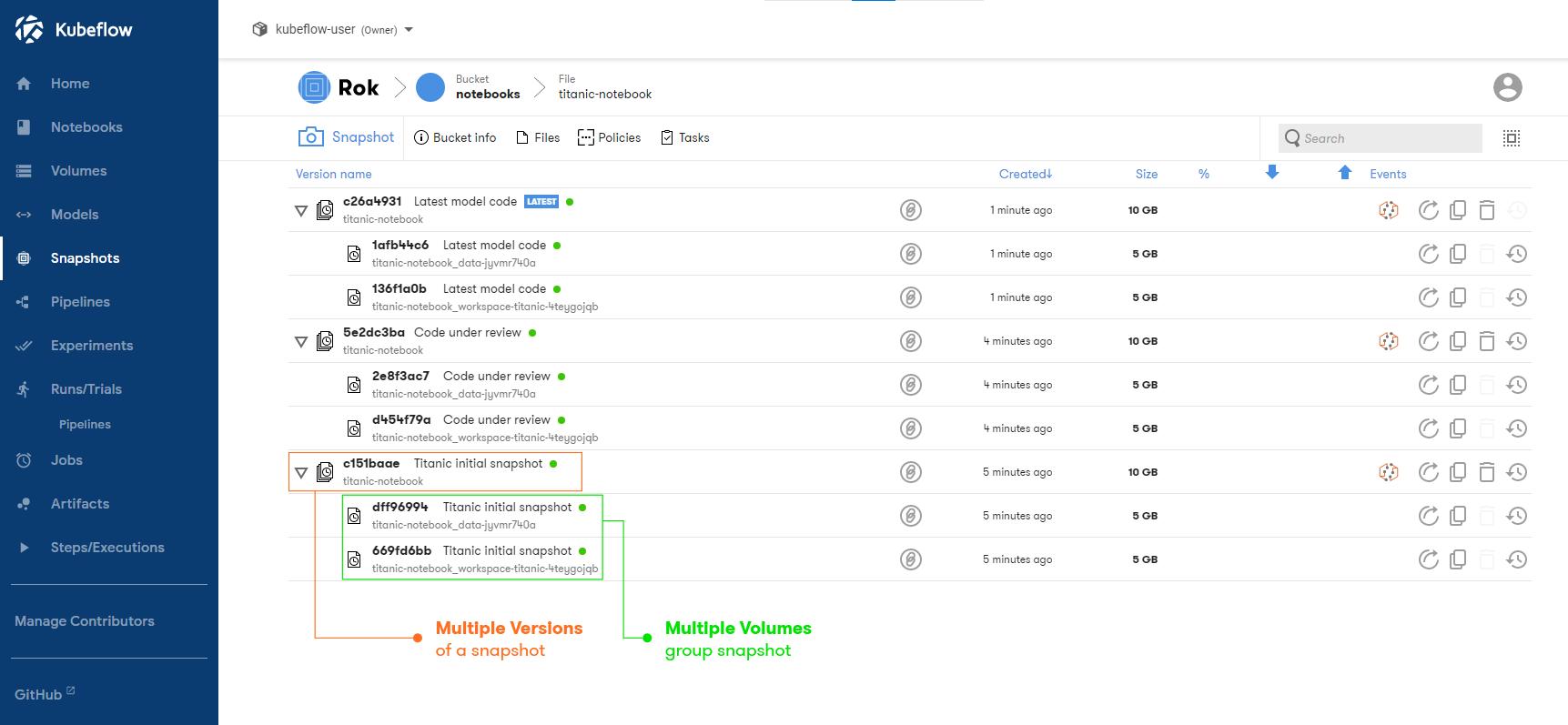
Team members can subscribe to each bucket and whenever data is updated, they automatically receive the latest version. This is a simple Pub / Sub model for data accessibility.
The data scientist subscribing to a data bucket has full control over which version of the data they wish to use, and can further accelerate their own processes and productivity by automating rehydration of versioned datasets for their own testing.
It is important to note that while each snapshot contains the entire dataset, only changes between versions are transferred between peers. This greatly reduces transfer time and network traffic costs.
Global Distribution and Self Serve Collaboration

Global data mobility is achieved through a decentralized network that allows for data synchronization between peers secured via end-user access controls.
The net result is that as each team member makes progress, they can share and “check-in” both their model code and data for peer review and feature development.
This is a huge advancement over the traditional copy / paste and data duplication of a centrally shared file server, data warehouse, or data lake.
Conclusion
Over the three parts of this Data as Code series, we’ve introduced the idea of treating your data as code for the same benefits as DevOps for application development, shown a real-world example of data mobility and global machine learning CI/CD, and given explicit examples of how individual data scientists and data science teams can collaborate.
DevOps along with agile methodologies have radically changed our IT practices for development, deployment, and operation of technology.
Until now, data practices haven’t really changed all that much since the 90s.
With Data as Code and Arrikto’s implementation, we now have productivity parity for data.
Core to our belief is that data should be end-user managed and application-centric.