

In part 1 of this series on Data as Code we discussed how software development practices have changed dramatically, yet the other half of the equation, data, hasn’t kept up.
Today we are going to explore this further and show an example of how we can manage data like we do software. Through this example, you will see how data pipelines are more than simply a DataOps process, but intrinsically part of your software development pipeline.
We are all familiar with the concept of code repositories, version control, mainline and feature branches, comparing and merging code – but have you ever wondered if you could do the same with data?
In today’s world, data truly is king and we’re building applications driven by rich experiences to connect with our customers and help us make better informed decisions.
Software development has advanced, but what happened to the data?
Marc Andreessen famously said “software is eating the world”, and he’s been right. So many companies today rely on their software development teams to deliver ever faster value. Some organizations take this “always Day 1” concept and constant release approach to the extreme with multiple releases per day.
The hardest problems today are being solved by data science teams that rely on machine learning and the consumption of multiple streams of data across a wide range of input sources. Some of them are traditional enterprise warehouses and ERP systems. Others come from customer interactions or social sentiment.
Most commonly, when a data scientist requires a set of data, they send a request to an application owner or DataOps team and receive a data dump.
What happens from there is left entirely to the discretion of the data scientist.
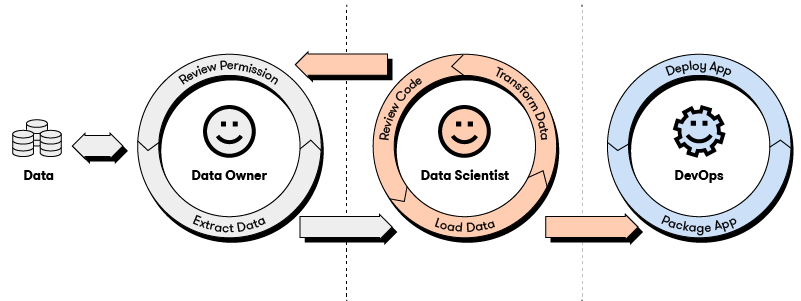
If we take the traditional approach, the data scientist will share this new data with their machine learning colleagues and begin iterating their model development in a tool like Jupyter Notebook, Visual Studio Code, or R Studio.
The data just exists as an amorphous blob, as machine learning models are written, checked into a git repository, versioned, branched, merged, and trained. Along the way, machine learning engineers improve their models and tweak hyperparameter settings, all the while having to monolithically manage multiple copies of the same data.
Invariably, the data needs to be modified, or an updated version be requested from the application team.
Once this happens, data science teams now have to manually keep track of model experiments against both a model and data version. They also need to train updated models against the entire dataset from scratch again, wasting precious time and resources.
Even for advanced users with automated ingestion pipelines consuming new incoming data and retraining relevant models, the original data source is typically mutable. This introduces additional challenges with respect to reproducibility, provenance, and lineage. The impact is unnecessary complications for debugging and the likelihood that your data scientists are unable to prove which dataset and model version produced specific outcomes.
That’s how things are today. When we apply Arrikto’s Data as Code principles to this problem, data scientists can easily “check-in” their data and keep track of multiple versions, branch and merge it, and instantly share synchronized model and data repos with their colleagues.
Imagine being able to take an instant snapshot of a dataset, match it to the corresponding versioned model code, and annotate with custom metadata.
Imagine tuning your models and promoting them through your lifecycle environments with the push of a button, completely packaged up so the production DevOps and MLOps engineering teams can simply release via your existing CI/CD pipelines.
Imagine coming back to a model and dataset months or even years later, being able to review commit logs for your model and datasets, update your data, and retrain your model with just the updated data changes.
You don’t need a vivid imagination. This is all possible today, right now.
Arrikto has applied the very same principles that enabled us to massively accelerate software development to data. And has done it in a completely Kubernetes-native way, so your infrastructure can actually scale.
Yes, data IS king – but until now no one has been there to organize your coronation.
Data as Code In Action
Let’s walk through some specific examples.
You’re a healthcare company providing state of the art monitoring for patients recovering from a heart attack. The devices you make are distributed globally to thousands of patients and you collect constant streams of data.
At this scale, you are required to deploy a multi-hybrid cloud architecture across Google Cloud and Amazon Web Services in North America, and Microsoft Azure in Europe. Each hospital also has data collection ingestion points that feed their closest cloud region.
You’ve deployed an Internet of Things (IoT) architecture with machine learning inference at the near edge for immediate patient feedback, which then sends batches of data to your core artificial intelligence processing system.
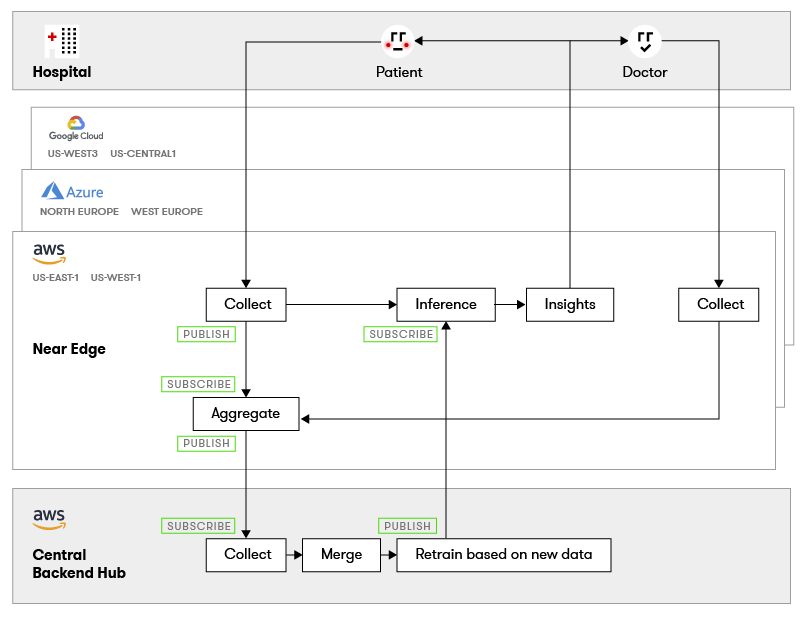
Here we see that the patients and doctors in hospitals across North America and Europe have access to the heart monitoring system. It is constantly collecting and analyzing data with feedback provided to both the patient and doctor. The doctor’s notes and corrections are also incorporated.
Because of the scale needed, you have deployed this machine learning and application architecture across multiple cloud regions and they are seen as near edge locations.
Data is batched up and shared back to the central data processing and machine learning hub for retraining before pushing out updated models to the near edge for improved diagnosis.
Native Data Packaging and Mobility
Here is where Data as Code takes over from the old way of doing things. Data is securely transported via a Publisher / Subscriber model, and most importantly, kept in the native format used by the application and machine learning model. There is no need to deploy complex messaging software like Kafka.
This means that you no longer need to extract data from your application, transform it into a Kafka message for transport, and then reverse it to load it back into your application.
Merging Data and Differential Retraining
Another benefit of Data as Code is being able to apply the same branch and merge operations software developers do. Because you are able to quickly and efficiently transport only the new data, and then merge it back into your original dataset, you can rapidly retrain your model with minimal resources.
This is exactly how code is managed today. Developers create a branch, develop the new feature or fix a bug, test it, then check in a new version before merging it back into mainline.
In the example above, you are doing the same thing, but with data. This is powerful because it allows you to not only version data, but keep track of which data is related to which model version. In the case of healthcare, reproducibility and policy compliance is crucial.
What’s Next?
This is just a small example of how Data as Code helps organizations accelerate the development, deployment, and operation of data rich applications.
In part 3 we’ll explore how Data as Code further enhances collaboration within and between teams, provides a unified data plane across any cloud, and achieves data anti-gravity.