

Response times for applications impact revenue and customer satisfaction, and are therefore mission critical. Whether your application is user facing, performing computational analysis, or providing integration between services no one wants to wait any longer than necessary. Thousands of applications rely on Apache Cassandra to store and retrieve this data, and DataStax Enterprise is the proven leader delivering the most reliability and performance.
Recently, DataStax introduced the DataStax Kubernetes Operator for Apache Cassandra to make it trivial to deploy and scale distributed clusters. Never happy to sit back and think the job is done, they’ve been looking at ways to further improve the performance and reliability as well as reducing your costs.
We partnered with DataStax to jointly perform a series of engineering tests and found an amazing 15x faster response time with a 22% transaction cost saving when using Amazon Web Services!
Christopher Bradford (DataStax Product Manager) and Arrikto’s Chris Pavlou (Technical Marketing Engineer) used Amazon Web Services EC2 instances and DataStax’s Cassandra benchmark tool to undertake a comprehensive review of the benefits DataStax customers can enjoy with Arrikto Rok data management platform.
How it works
Arrikto Rok is a revolutionary storage and data management solution for stateful applications on Kubernetes. The biggest difference between Arrikto’s approach and that of legacy Software Defined Storage solutions is that Arrikto enhances existing local storage devices’ data management capabilities rather than inserting an additional layer of abstraction. Abstraction layers always introduce latency and slow down IO. High latency and slow storage is not what you want for your data services.
Arrikto stays out of the critical data path and instead integrates data management capabilities through patented snapshot technology and new contributions to the mainline Linux kernel.
This means when your application reads and writes to storage, it does so to a local disk. In a cloud environment, this is even more impactful, because it means you can use significantly faster AND cheaper storage with already existing local NVMe options, instead of network attached AWS EBS, Azure Disk, or Google Persistent Disk.
Arrikto Rok enables data management, versioning, and transport in a managed way so you can ensure the highest performance for normal operations and very fast recovery. This architecture also delivers low cost of both disk storage and operations.
The important outcome of this is that Arrikto enables ephemeral NVMe disks to become primary persistent storage in a way that wasn’t possible before.

Testing Architecture and Configuration
To make the case, DataStax and Arrikto chose to run the open-source NoSQL benchmark tool nosqlbench, and compared two different scenarios on AWS. The exact same architecture would apply for any other cloud provider or on-prem deployments. In the case of AWS, the comparison took place between:
Common cloud-managed attached disk
3 node Cassandra cluster running on a 4 node Kubernetes cluster with AWS managed Elastic Block Storage (EBS) Disks. The fourth Kubernetes node enables a “recover from failure” scenario, where we terminated a Kubernetes node in AZ1 and recovered it in a different zone (AZ2) – a more realistic example of desired customer architectures.
The Kubernetes nodes hosting the Cassandra pods run on AWS instances with AWS EBS volumes attached for cluster data storage. With EBS, all I/O requests go over the AWS backend storage network.
Cassandra was scheduled to run with only a single pod per Kubernetes node, with a spare Kubernetes instance to handle recovery operations.
In this example, all nodes were in the same Availability Zone (AZ1) due to single AZ limitations of EBS.

When you need to recover a failed Cassandra node, you are reliant on EBS operations and speed. EBS detach and reattach operations are notoriously slow and unreliable. Importantly, you can only detach and reattach an EBS volume within the same Availability Zone (AZ). This introduces significant latency to recovery operations as well as operational overhead to ensure the disk was actually moved correctly.
A True Cloud Approach with Arrikto
3 node Cassandra cluster running on a 4 node Kubernetes cluster with local ephemeral AWS local NVMe disk and Arrikto Rok. The fourth Kubernetes node enables a “recover from failure” scenario, where we terminated a Kubernetes node in AZ1 and recovered it in a different zone (AZ2) – a more realistic example of desired customer architectures.
In this architecture, Arrikto Rok gets deployed via the Rok operator on each Kubernetes node and connects to AWS S3 for storing the local volume snapshots. Cassandra consumes the locally attached ephemeral NVMe volumes. Thus all IO requests stay local to the Kubernetes node and do not traverse the AWS backend storage network. Data protection is provided automatically by local snapshots stored in S3.

When you need to deploy a new Cassandra node, or recover from a failure, Arrikto Rok queries the versioned immutable snapshots stored in AWS S3 and performs a fast pull to restore to local disk and re-hydrate the data. This also allows you to restore to any Availability Zone – you are not limited to the original AZ.
Summary of Results
Using the same DataStax benchmark for both architectures, we found significant performance differences between the commonly used EBS model vs Arrikto’s innovative approach.
Overall, using Arrikto Rok we found performance improvements across the board in Operations per Second, Read Latency, and Write Latency.
Operations per Second saw improved performance starting at 10% and peaking at 55x faster than EBS* before the test failed to complete.
Latency improvements across Read Heavy, Write Heavy, and Balanced Read Write was also significant. Read Heavy latency was 26x better with Arrikto Rok vs AWS EBS* – that is an improvement of over 96%!
Write intensive latency also improved by 52% – that’s a 2x speed increase*.
* In many of these scenarios, EBS was simply unable to complete the test. The results reported for both EBS and Arrikto Rok are the output of EBDSE (DataStax benchmark tool) at the time the test ended.
When we take into consideration straight EC2 cost differences of using NVMe instances instead of EBS instances, you can save approximately 15% on your AWS bill – while also seeing massive performance increases. When you consolidate your instances into fewer larger instances, we saw cost savings up to 40%.
Drilling down even deeper, the cost per transaction ($ / OPS) also saw a reduction in cost of 22% for write intensive workloads.
Detailed Results
Breaking down the results, we compare performance, cost, and operational overhead.
Performance
To compare the performance benefits, we ran a suite of tests. We had a DSE cluster with EBS-backed instances and a DSE cluster with NVMe-backed instances. In both cases, we used i3.8xlarge instances. As shown, the difference between EBS and NVMe is huge in terms of operations per second and latency.
The first test was write intensive (10 / 90% R/W), and we noticed 10% better performance in ops, 5 times better read latency, and 2 times better write latency. This was followed by a 50-50 read/write test (50 / 50% R/W), where we noticed 12 times better performance in Cassandra ops, 32 times better read latency, and 9 times better write latency. The most impressive results came from the read-intensive workload (90 / 10% R/W), where we found 55 times more Cassandra ops, 26 times better read latency, and 15 times better write latency.
Tables of results with specific numbers are below the graphs.
Note: Metrics marked in RED denote that EBS-based configurations failed to complete the job. nosqlbench clients aborted with client timeouts because the DSE cluster failed to keep up with the excessive load.
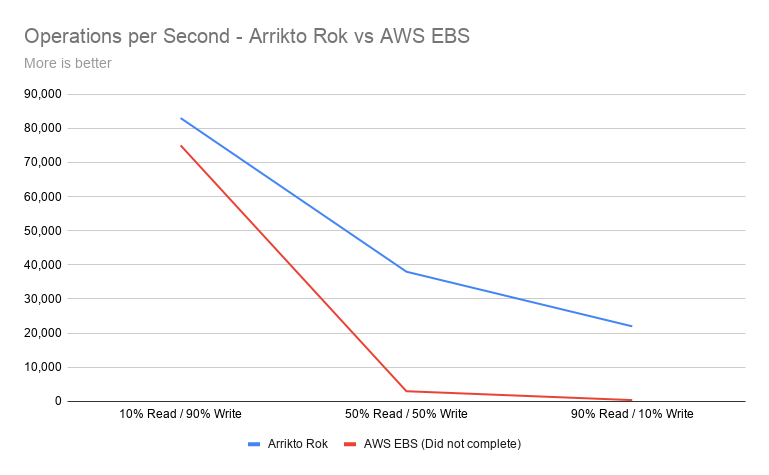
| IO Profile | Arrikto Rok | AWS EBS | Improvement |
| 10% Read / 90% Write | 83,000 | 75,000 | 10% |
| 50% Read / 50% Write | 38,000 | 3,000 | 12x |
| 90% Read / 10% Write | 22,000 | 400 | 55x |
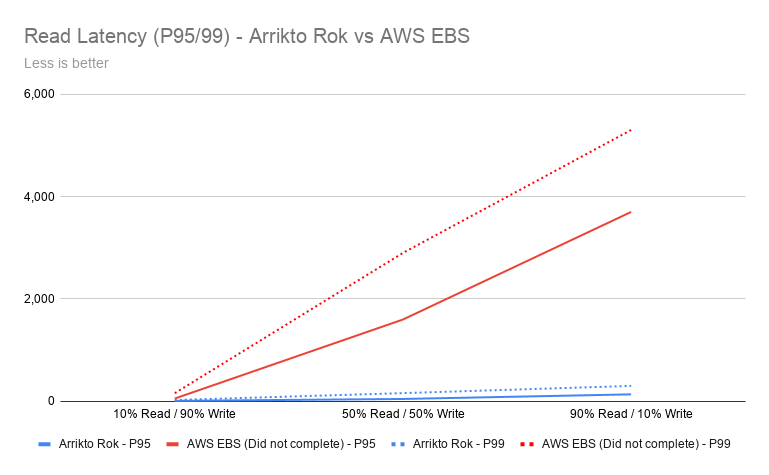
| IO Profile | Arriko Rok | AWS EBS | Improvement | |||
| Milliseconds | P95 | P99 | P95 | P99 | P95 | P99 |
| 10% Read / 90% Write | 12 | 28 | 57 | 162 | 4x | 5x |
| 50% Read / 50% Write | 49 | 163 | 1,600 | 2,900 | 32x | 17x |
| 90% Read / 10% Write | 138 | 304 | 3,700 | 5,300 | 26x | 17x |
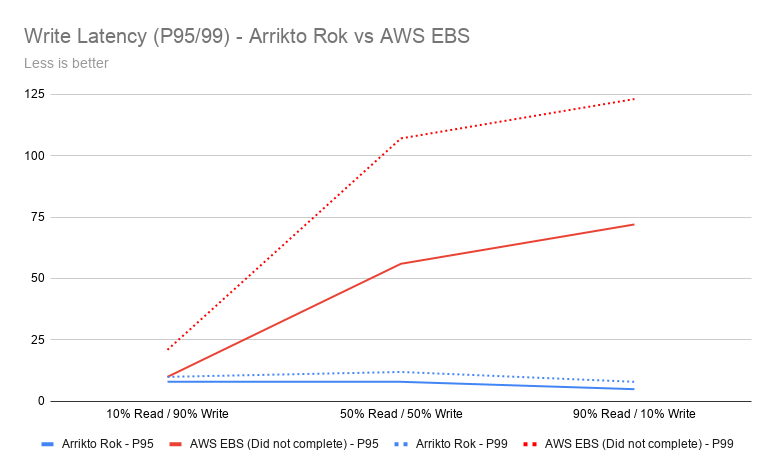
| IO Profile | Arriko Rok | AWS EBS | Improvement | |||
| Milliseconds | P95 | P99 | P95 | P99 | P95 | P99 |
| 10% Read / 90% Write | 8 | 10 | 10 | 21 | 1x | 2x |
| 50% Read / 50% Write | 8 | 12 | 56 | 107 | 7x | 9x |
| 90% Read / 10% Write | 5 | 8 | 72 | 123 | 14x | 15x |
Cost
In our testing, both architectures used similarly configured AWS instances with the exception that the commonly deployed EBS configuration used an r5 series Memory Optimized instance for EBS, while the Arrikto Rok configuration used an i3 series Storage Optimized instance for NVMe support.
Storage arrays, SDS solutions, cloud native storage solutions, and cloud vendors’ managed block and file solutions are more expensive. They are also much slower than NVMe SSDs.
Further, to scale performance with AWS EBS you must also increase the capacity. General Purpose (gp2) EBS IOPS are directly related to capacity at a ratio of 3 IOPS / GB, so the 1 TB EBS volumes were limited to a maximum of 3,000 IOPS. To further conflate this issue pricing for EBS volumes is directly tied to capacity. Overprovisioning capacity to increase IOPS directly results in increased costs even if not all of the volume is in use. This is a major challenge when planning performance and cost optimized solutions in the public cloud.
Using super-fast NVMe drives not only makes your applications run faster, but also reduces your total cost of ownership (TCO). When running on the cloud, leveraging NVMe-backed instances showed that we reduce the TCO from 15% to 40% depending on the use case. This is even more true when running in your own datacenter as NVMe drives have a far superior Annual Failure Rate of tenths of one percent vs 4 – 8% for spinning disks.
The table below shows the performance and cost benefits when running a 100-node Cassandra cluster using NVMe-backed instances on AWS compared to EBS-backed instances.
To understand a real world example of how you would select instance types and their cost, we modelled the following;
| Instance Type | r5.8xLarge | i3.8xLarge |
| Number of Instances | 100 | 100 |
| Total vCPUs | 3,200 | 3,200 |
| Total RAM (GB) | 25,600 | 24,400 |
| Storage Type | EBS | NVMe SSD |
| Storage Capacity (TB) | 5.334 | 7.6 |
| Total Nominal IOPS – Read (K) | 1,600 | 165,000 |
| Total Nominal IOPS – Write (K) | 1,600 | 72,000 |
| Latency | Single-digit milliseconds (ms) | Double-digit microseconds (μs) |
| Total Price per Year (USD) | $1,752,600 | $1,501,464 |
That’s a straight line saving of $251,136 per year, almost 15%.
When we compare the cost per transaction, we get an even more interesting picture
The $ / IOPS on naked front-end IOPS is simple to calculate.
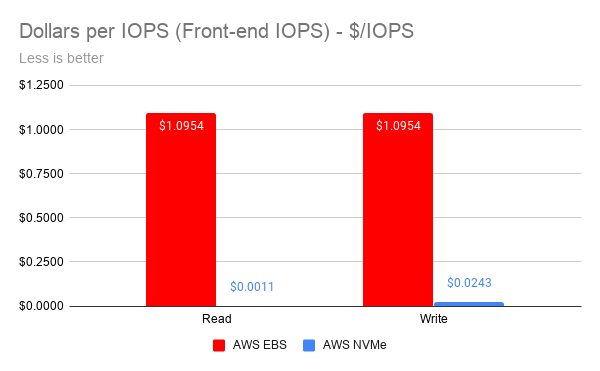
| IO Profile | AWS NVMe | AWS EBS | Improvement |
| Read | $0.0011 | $1.0954 | 99.90% |
| Write | $0.0243 | $1.0954 | 97.77% |
When you now look at how that compares to actual Cassandra throughput using EBS and Arrikto Rok, you can see real world impacts.
| IO Profile | EBS | Arrikto Rok | Improvement | ||
| Op/s | $/op/s | Op/s | $/op/s | ||
| 90 / 10% RW | 400 | $4,381.50 | 22,000 | $68.25 | 98.44% |
| 10 / 90% RW | 75,000 | $23.37 | 83,000 | $18.09 | 22.59% |
When you consider what these $ / operation costs mean, you can dramatically reduce your Kubernetes node cost. This has further indirect cost saves from your cloud vendor. More if you are using a managed Kubernetes service from either your cloud vendor or another 3rd party ISV.
Whichever way you look at these numbers, Arrikto delivers stunning results.
Ease of Operations
The benefits we documented are not just (JUST!) limited to simply performance and cost.
Operational overhead is a real problem and impacts how you hire and train your teams, and manage your applications. One large SaaS provider using a well known cloud-native software defined storage product for Kubernetes would regularly spend over 20 hours every time they had to manually scale cloud disk capacity.
Then you have availability impacts to take into consideration.
EBS volumes are replicated within a single Availability Zone (AZ). This means that if an AZ goes down, the EBS volume won’t be available on a different AZ. Thus, the Cassandra node won’t be able to migrate its data to a different AZ. If possible, a new node would need to be provisioned and bootstrapped by pulling data from existing replicas. This process is automated via cass-operator, but takes time.
Arrikto Rok dramatically improves Recovery Point Objective (RPO) and Recovery Time Objective (RTO), which means applications are available faster. Rok’s core technology creates and tracks virtually unlimited snapshots of local persistent volumes, which do not impact application performance, because they are kept separate from the critical I/O path. It hashes, de-duplicates, and versions these snapshots, and stores the de-duplicated, content-addressable parts in an Object Storage service that is close to the Kubernetes cluster, in our case Amazon S3. It also allows restoring these snapshots, on new local volumes, on any other node, across availability zones, hydrating them from the Object Storage Service. All in an automated manner, transparently to the application and Kubernetes.
To make the above case, we ran a “recovery from a node failure” scenario on a Kubernetes cluster on AWS with significant capacity, 1.5TB volumes, to simulate a demanding production environment. When we terminated one of the DSE nodes, Kubernetes rescheduled the node to a different AZ, and Arrikto Rok recovered the PVC of the failed DSE pod from the latest Rok snapshot automatically. Everything happened with no human intervention, transparently to both Kubernetes and Cassandra.
Testing showed this would take over 10 hours if Cassandra application-level replication was required combined with significant cluster performance impact. Using Arrikto Rok, the new DSE pod came up in the new Availability Zone and successfully joined the cluster in 15 minutes.
An alternative configuration for Arrikto Rok allows for instant availability with temporarily increased latency for the specific Cassandra node during recovery – without imposing a cluster-wide performance impact.
With Arrikto Rok, Cassandra does not invoke an application-wide data recovery and rebalancing operation, which puts load on the whole cluster and impacts application responsiveness.
Instead, Rok performs block-level recovery of this specific node from the Rok snapshot store with predictable performance.
When using Arrikto Rok, the new DSE node already has the data of the latest Rok snapshot and Cassandra only has to recover the changed parts, which are just a small fraction of the node data.
What this means
So, what does this actually mean?
It means when you use Arrikto Rok, you get the following business benefits;
- Dramatically increased throughput of up to 55x for read intensive workloads
- Radically faster response times of up to 32x for balanced read / write workloads
- Impactful cost saving of at least 15% on similarly configured environments
- Massively reduced cost of data transactions by at least 22%
From a technical perspective, this enables you to;
- Completely eliminate AWS EBS
- Deliver high levels of availability across multiple Availability Zones
- Reduce wasted staff time managing cloud disks
- Deploy smaller clusters with the same performance and lower cost
- Slash your software bills for Kubernetes
Putting it succinctly, Arrikto Rok allows you to take a true cloud approach to containerized storage and data management. Rather than simply putting a software-defined storage layer into a container, Arrikto has taken a new approach that is actually container-native.
Conclusion
DataStax has consistently been the best option for running Cassandra on-prem or in the cloud. The DataStax Kubernetes Operator for Apache Cassandra has made deploying and scaling distributed clusters more efficient and easier than ever before.
When it comes to storage, with Arrikto Rok, for the first time you can bridge the performance of NVMe with the flexibility of a shared network attached storage option. Arrikto Rok makes your apps performant and at the same time truly resilient and portable, at a fraction of the cost of a shared storage solution.
We believe that this revolutionary new architecture and the partnership between DataStax and Arrikto will dramatically improve the way people run Cassandra both on-prem and on the cloud, and will open the door to new workflows that were never possible before.