

Welcome to a world of Fisks
Trying to build independent Data Services with a top-down approach, starting from the platform and moving towards Storage, presents us with a great challenge.
There seems to be a strong coupling between the resources known to and handled by a virtualization/container or even bare metal platform, and the resources exposed by today’s persistent storage technologies.
In this article we’ll describe this resource coupling and the blockers it presents for building independent Data Services. We discuss a new approach, which allows us to uniformly expose and consume resources independently of platform and underlying storage technology.
Resource Coupling
In today’s world of VMs, Containers, Cloud, and bare metal infrastructure, we come across a multitude of platforms (e.g., VMware, Azure, OpenStack, AWS, GCP, Docker, Kubernetes, CoreOS, Linux), each one trying to manage and pair Storage with the Compute resources it handles, so it may be consumed accordingly. Platforms, from their perspective, use a variety of data abstractions to access and manage the resources they need. Looking at the way platforms refer to Storage, we start talking about:
Disks, Volumes, Snapshots, Images, Ephemeral Disks, Persistent Disks, Backups, Templates, ISOs, and the list goes on as we dig into more platforms.
The reason why platforms introduce the above resources is because there are distinct storage needs in terms of qualitative (reliability, durability, availability, compliance) and quantitative (IOPS, latency, bandwidth, QoS, interference) characteristics, the combination of which results into a different set of usage requirements. Platforms need to cater to these requirements and present them to the end user. For example a user or application may need a very fast VM disk which is not very critical if lost, and thus will choose an Ephemeral Disk. Or, they may need a rock-solid disk that will hold critical data to back a database, and thus choose a Persistent Volume.
On the other side of the table, we have persistent storage technologies that platforms rely upon to back these requirements. Storage technologies do not expose or manage high level resources like the above. Looking at the way storage products refer to their resources, we start talking about:
Files, LUNs, Blocks, Objects, Blobs, Storage Management APIs
Since the platforms need to use the underlying persistence technologies to satisfy their requirements and back their high level resources, where do the two worlds meet?
Current Approach
Easy! Currently, all platforms do a one-to-one mapping to back their resources.
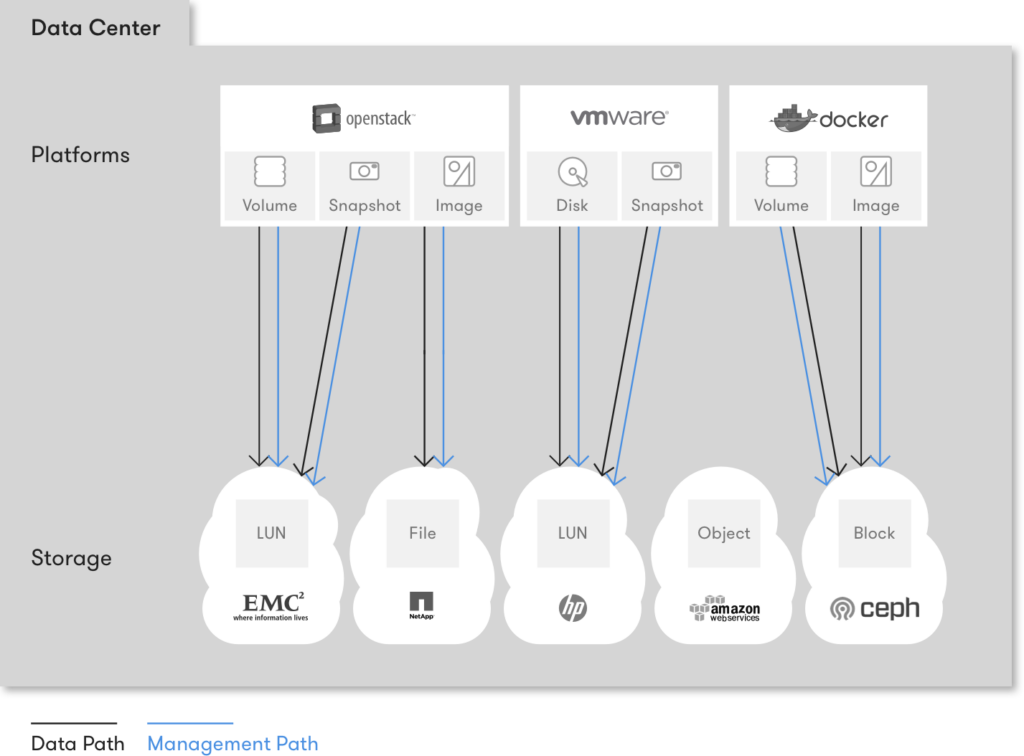
This means choosing a persistence technology that covers the requirements of the platform’s specific resource as close as possible, and directly associate the platform resource with the storage resource of that technology.
The result is:
- A platform’s Image gets backed by a file on Storage Product 1
- A platform’s Volume gets backed by a block device on Storage Product 2
- A platform’s Snapshot to be archived gets backed by Storage Product 3
In the most sophisticated case, one storage product backs more than one of the platform’s resources, but then compromises regarding the resource’s required characteristics are inevitable, since no Storage product fits all use cases well.
Result
The result of one-to-one mapping is that platforms get fragmented on two levels. They split storage processing internally, even with distinct codebases per usage pattern or per resource to be handled. The two levels are:
1. Service level
Platforms need to implement separate services altogether to manage different types of resources. See:
- Docker: Image Service vs. Volume Service
- OpenStack: Nova ephemeral Disks vs. Glance Images
vs. Cinder Volumes vs. Cinder Snapshots - AWS: Images vs. Instance Store vs. EBS
- VMware: Hypervisor manages disks as part of VMs,
Snapshots managed implicitly
Although managing very similar storage resources underneath, different services pop up on all modern platforms. Multiple services result in even more complicated problems down the road, which have to do with service coordination, coherence, transactional support, and recovery from failure.
2. Driver level
For each service a platform implements, it now needs to integrate with more than one underlying Storage technology to cater to the different usage requirements. Thus, a driver API for both access and management is needed. By ‘access’ we refer to the actual data path, where I/O requests (read, write) flow, via an I/O fabric. By ‘management’ we refer to a way of creating, removing, and discovering storage resources. These APIs are very similar, nevertheless implemented multiple times, one for each service, sometimes by different development teams altogether. See for example:
- Docker Storage Driver API vs. Docker Volume Driver API
- Nova Libvirt Volume Driver API vs. Cinder Volume Driver API
vs. Glance Store API
Being so fragmented, they may or may not cover the whole functionality of the vast number of underlying storage products. It is then left to the vendors or integrators to implement the corresponding drivers, for each product and for each service independently.
Another problem is that platform services are now glued to the underlying persistent storage product. The resources of the service are limited by the Data Services confined inside a single storage box, either physical or virtual. It doesn’t matter if the architecture is converged or hyper-converged, sophisticated or not, with a storage product that is “intelligent” or not. Once the administrator chooses a specific storage product to back a specific platform service, they are stuck with this product’s Data Services.
So, how are we going to implement unified, intelligent Data Services that will extend the functionality of the platform itself, if the only Data Services we can use are the traditional ones provided by the storage product we’ve chosen (proprietary services like mirroring, caching, dedup, QoS)?
If we map one-to-one, we get shut off the data access and management path. We cannot decouple Data Services from the box and be able to operate across platforms, across locations and across persistence technologies. Essentially, if we map one-to-one platform resources (Disks, Volumes, Snapshots, Images, etc.) to storage resources (Files, LUNs, Blocks, Objects), we cannot implement independent Data Services.
Resource Decoupling
The need for independent Data Services, which will free the platforms from having to care about how data is persisted, and instead enable them to consume it in the required form every time, implies the need for a new, different mapping than the current one-to-one we have described above.
It calls for a new, intermediate data abstraction that will sit between the platform resources and the storage resources. A new virtual resource that did not exist before and will live on the distinct Data Services layer, below the platform layer and above the persistence layer.
We call this resource: A Fisk!
Fisk comes from File and Disk. A Fisk is a linearly-addressable set of blocks. It doesn’t matter exactly what kind of resource the underlying persistence technology exposes, be it a file, a LUN, a block device, or a big object of a few MBs; as long as it’s meant to be accessed by referring to specific block numbers inside it, e.g., “read five blocks starting at block 20,” it’s a Fisk.
The resource by itself only solves half of the problem, though. One needs a way to access and manage a Fisk. Same as before, by ‘access’ we refer to the actual data path, where I/O requests flow, directed to a Fisk, while by ‘manage’ we refer to a management path that allows upper layers to provision and manipulate Fisks.
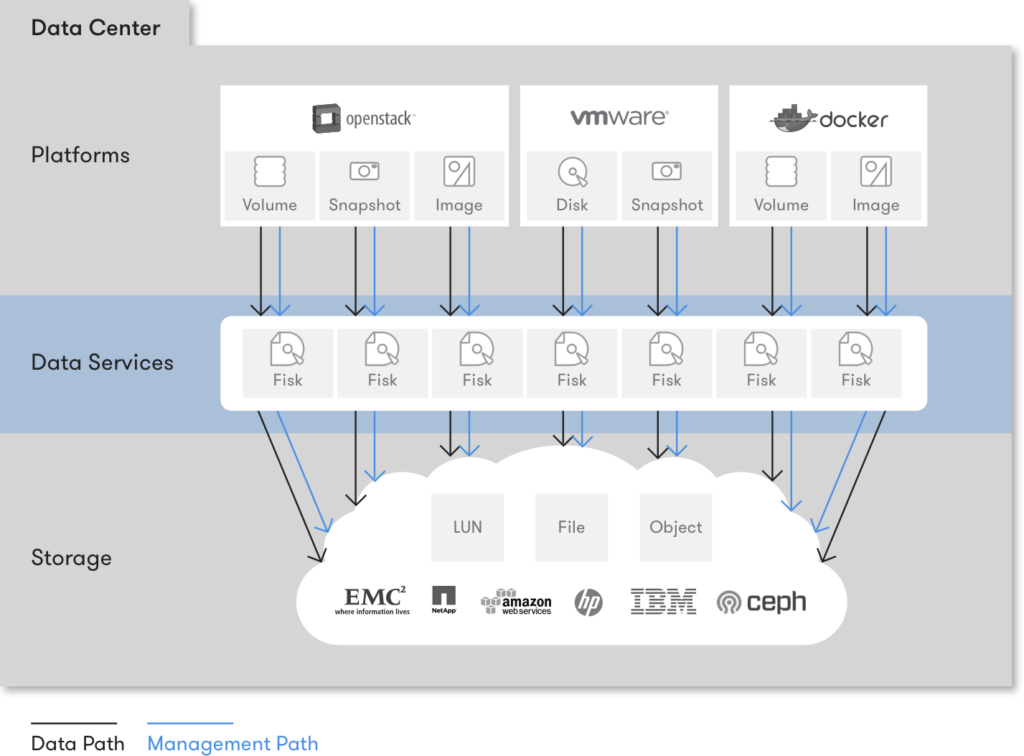
By having a new virtual resource which platforms can access and manage in a standardized way, and simultaneously having this resource access and manage the underlying persistent storage resources, we have now completely decoupled platform resources from storage resources, for the first time!
The future
We can now have a single data abstraction backing the resources of all services on all platforms. Talking about Images, Volumes and Snapshots immediately becomes talking about the same thing. Everything is indeed one: a different representation of a Fisk.
Not only do platform resources become projections of the same entity, they are also completely independent of the underlying storage technology. A Fisk can eventually be stored anywhere we like, depending on our requirements, which are not dictated by the platform anymore. Planning for data persistence gets for the first time decoupled from planning for a platform’s usage requirements. The administrator can now choose separately how to deploy the platform and how to purchase persistent storage without the one affecting decisions on the other. The door is also wide open for us to implement independent Data Services that will operate on Fisks and provide uniform functionality across platforms, locations and persistence technologies. The time has come.
See you in VMworld US 2016 in less than 10 days, and remember:
Don’t try and store the Images.
Instead, only try to realize the truth.
There are no Images.