

Kubeflow is an open-source project dedicated to making deployments of machine learning (ML) projects simple, portable, and scalable. In reality, Kubeflow is a suite of components like Notebook Servers, Pipelines, Katib, KFServing, MLMD, and Volume Manager. There are also additional tools like Kale, an access management via Istio/OIDC, Rok for data/code/pipeline/model versioning from Arrikto, which can be used in conjunction with Kubeflow, to make for a more complete MLOps platform. The goal of any MLOps platform should be to enable data scientists to better handle their infrastructure needs, while at the same time make it easier for operations folks to more efficiently operationalize the models that data scientists have created. As with any large, complex deployment that requires tight integration between hardware, software, people and processes, plus has a strong sense of business urgency attached to it, technical debt will surely add up quickly.
First, Some Context…
In 2015, Google introduced the concept of technical debt in ML lifecycle with their paper “Hidden Technical Debt in Machine Learning Systems” by D Sculley et.al, which was mostly overlooked then, but now with a rapid adoption of ML in industry and academia , the focus on ML technical debt have increased and over 50+ papers have been surfaced in top tier conferences like ICML, NIPS etc.
When software engineers prioritise speed of deployment over all other factors in development, the build-up of these ongoing costs is referred to as “technical debt”. The issues arising from fast-builds can take an awful lot of work to fix down the road. However, technical debt is considerably worse for ML systems with the sheer number of tools, languages, techniques and applications a machine learning ecosystem has nurtured. Choosing the best fit out of these hundreds of options and then bringing them together to work seamlessly is a data scientist’s nightmare. The hidden technical debts in an ML pipeline can incur massive maintenance costs.In this blog, I’ll discuss issues I have experienced working as a Data Scientist in fast moving ML teams at companies like Halodoc, Onepanel and Leadics, and also will present ways to solve them, best practices and how Kubeflow can help in solving them for small teams and enterprise companies alike.
A Typical Machine Learning project:
Almost any ML project can be described in the following nine steps:
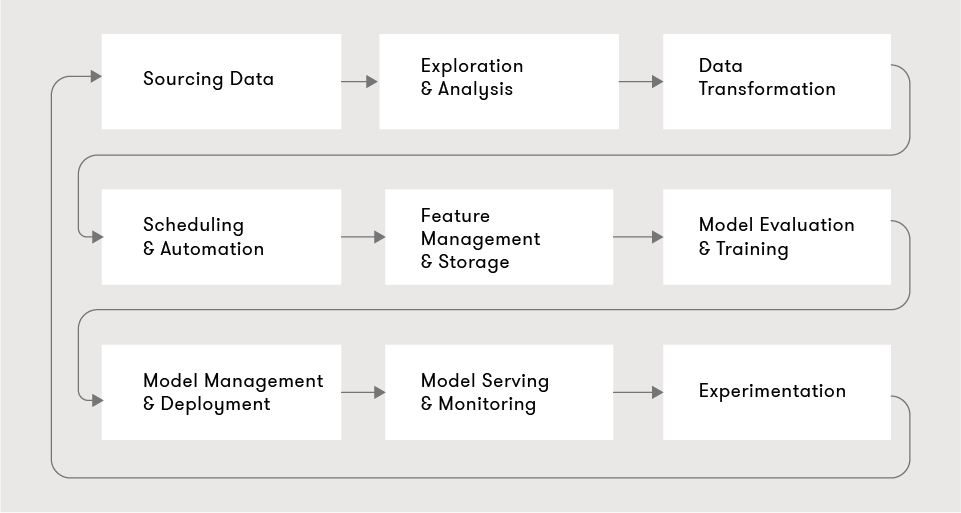
We start by sourcing data, then a data scientist explores and analyzes the data, attempting to derive insights. The raw data is then transformed into valuable features, typically involving scheduling and automation to do this regularly. The resultant features are stored and managed in a feature store, available for the various models and other data scientists to use. As part of the exploration, the data scientist will also build, train, and evaluate multiple models, in most cases hyperparameter tuning is done using Bayesian Optimization, HyperBand etc. Promising models are then stored and deployed into production. The production models are then served and monitored. Typically, there are numerous competing models in production, and choosing between them or evaluating them is done via experimentation or A/B tests and canary deployments. With the learnings of the production models, the data scientist iterates on new features and models.
Typically, data science teams follow a common pattern to develop and deploy ML models:
- A data scientist develops model and training code in siloed notebooks or other coding environments running in local machines, on-premise or cloud infrastructures.
- A data scientist trains the model on data stored in a database or files (csv, txt, images etc).
- A data scientist partners with a backend engineer to deploy the trained model as an inference service.
- The backend engineer creates the API proxies required for applications outside of the project-specific account to call the inference service.
- DevOps and other engineers perform additional steps to meet company specific infrastructure and security requirements.
So, What’s the Problem?
While it’s not immediately obvious, the following hidden problems can cost the team in performance, and effect project deliveries and maintenance in long run:
- The ML development experience can be painful: Data scientists are in many ways expected to be full-stack engineers and to be able to take projects end-to-end. But some of the systems and tools they are provided are either painful to use or immature. Taking a model to production requires active participation from software engineering, DevOps and security alongside the data science team, as no engineer has the skills, software or understanding of the processes to do it alone.
- No standard ML life cycle: In principle, most data science projects should follow a very similar life cycle. However, a common problem is a divergence and lack of standardization at various stages of the ML life cycle. Data Scientists define their approaches to solving problems — which leads to a lot of duplicated effort.
- Challenging to get data science systems into production: The project life cycle for ML systems is typically in the order of months. A considerable amount of time is spent on the engineering (infrastructure and integration) bits compared to data science or machine learning.
- Data science systems are hard to maintain in production: Historically, these systems have been built as proof-of-concept (POCs) or minimum viable products (MVPs) to ascertain their impact first. This causes a problem when scaling to large numbers of model variants and environments. The fact that these systems are relatively brittle means that improvements cannot be made at the necessary frequency.
Enter MLOps: Kubeflow
MLOps is an ML engineering culture and practice that aims at unifying ML system development (Dev) and ML system operation (Ops). MLOps enables teams for automation and monitoring at all steps of ML system construction, including integration, testing, releasing, deployment, and infrastructure management.
Wait, what is Kubeflow?
The Kubeflow project is dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable. The goal is not to recreate other services, but to provide a straightforward way to deploy best-of-breed open-source systems for ML to diverse infrastructures. In this blog, We’ll be looking at Arrikto Enterprise Kubeflow, a complete MLOps platform that simplifies, accelerates, and secures the machine learning model development lifecycle with Kubeflow.
The vision for an MLOps platform at a company should be to empower data scientists to create ML solutions that drive direct business impact. These solutions can range from simple analysis to production ML systems that serve millions of customers. The MLOps platform should provide these users with a unified set of tools to develop and confidently deploy their ML solutions rapidly. There are two broad advantages to employing a MLOps platform:
- Makes it easy to compose ML solutions out of parts of the platform: New projects should formulate solutions out of existing products on the ML platform instead of having to build them from scratch. With the infrastructure complexity abstracted away, ML’s entry barrier to driving business impact is lowered. It would allow a data science team or even non-data scientists to leverage the power of machine learning.
- Best practices are enforced and unified at each stage in the machine learning lifecycle: Data scientists should have a clear understanding of all the stages of the ML life cycle, the tools that exist at each stage, and how to apply them to their use cases in a self-service manner with minimal support from engineers. This extends data scientists’ capabilities, who can now deploy intelligent systems into production quickly, run experiments with small slices of traffic confidently, and scale their systems to multiple environments, markets, and experiments quickly.
Standardizing the ML workflow with Kubeflow
Kubeflow’s stated mission is to standardize ML workflows by removing the need for specialized tools and products at each step of the project lifecycle.
Containerizing ML Workflow
Containers are lightweight, neat capsules for hosting applications using a shared operating system as opposed to virtual machines that require emulated virtual hardware. Docker enables us to easily pack and ship applications as small, portable, and self-sufficient containers that can run virtually anywhere. We should remember that Containers are processes, VMs are servers . It is not a common practice to train ML models in a containerized fashion. Most people tend to use simple Python scripts and requirements.txt files. However, it can be argued that “containerizing” training code can save a lot of time and trouble throughout the life cycle of an ML development. Containerizing a step allows us to re-run the step on a new data distribution effortlessly. Also, containerization facilitates running the job periodically — or upon a drop in performance on the monitored metrics, test and deploy it automatically, ensuring that the predictions are consistent and our users are happy.
Notebook Servers
Jupyter notebooks work well in Kubeflow because they can easily integrate with the typical authentication and access control mechanisms you may find in an enterprise. With security sorted out, users can then confidently create notebook pods/servers directly in the Kubeflow cluster using images provided by the admins, and easily submit single node or distributed training jobs, vs having to get everything configured on their laptop.
Kubeflow Pipelines
A pipeline is a description of an ML workflow, including all of the components in the workflow and how they combine in the form of a graph. The pipeline includes the definition of the inputs (parameters) required to run the pipeline and the inputs and outputs of each component. A pipeline component is a self-contained set of user code, packaged as a Docker image, that performs one step in the pipeline. For example, a component can be responsible for data preprocessing, data transformation, model training, and so on.
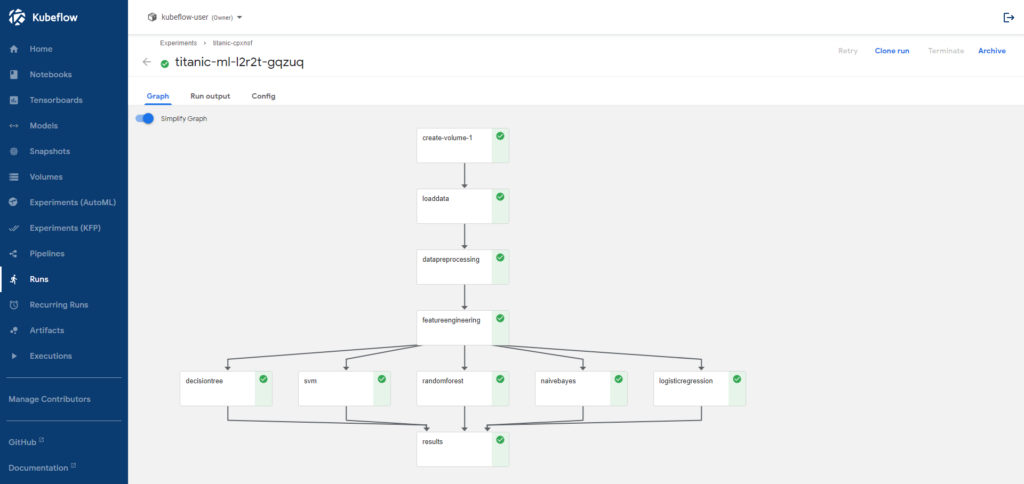
Using Kubeflow pipelines, Data Scientists can build and deploy portable, scalable ML workflows based on Docker containers. These Docker containers are custom built by the team with all necessary libraries and packages installed and ready to use. Pipelines also allow for end-to-end orchestration by enabling and simplifying the orchestration of machine learning pipelines, easy experimentation by making it easy to try numerous ideas and techniques, and manage your various trials/experiments. Pipelines also allow the reuse of components and pipelines to quickly create end-to-end solutions without having to rebuild each time.
Katib
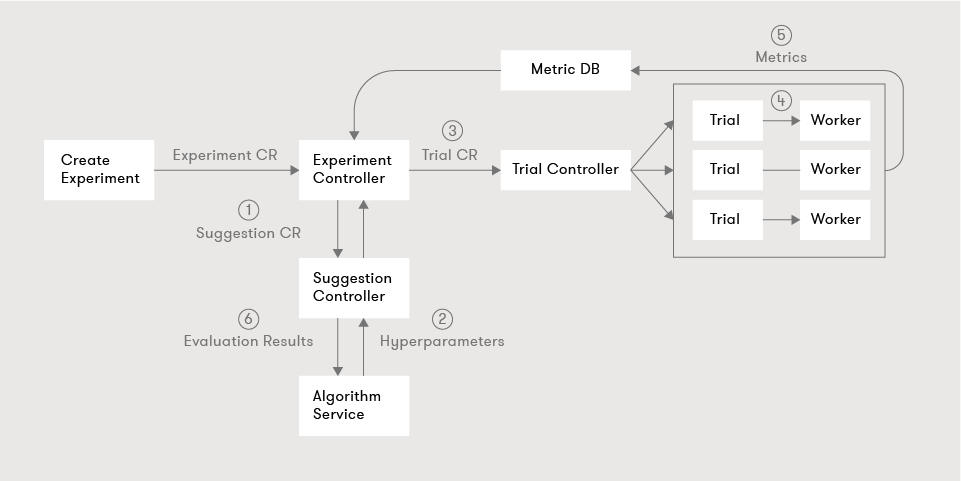
Katib provides automated machine learning (AutoML) in Kubeflow. Katib is agnostic to machine learning frameworks. It can perform hyperparameter tuning, early stopping and neural architecture search written in a variety of languages.
Kale
Since most data scientists like to use Jupyter Notebooks for building ML solutions, using Arritko’s open source Kale SDK, data scientists can generate Kubeflow pipelines from notebooks with a click of a button. Starting with tagging cells in Jupyter Notebooks to defining pipeline steps, hyperparameter tuning, GPU usage, and metrics tracking. Kale creates pipeline components and KFP DSL, resolves dependencies, injects data objects into each step, and deploys the data science pipeline.
Kale can also scale up the resulting pipeline to multiple parallel runs for hyperparameter tuning using Kubeflow Katib. Kale also integrates with Arrikto’s Rok data management platform to efficiently make the data available across Kubeflow components in a versioned way, and snapshot every step of each pipeline, making all pipelines completely reproducible.
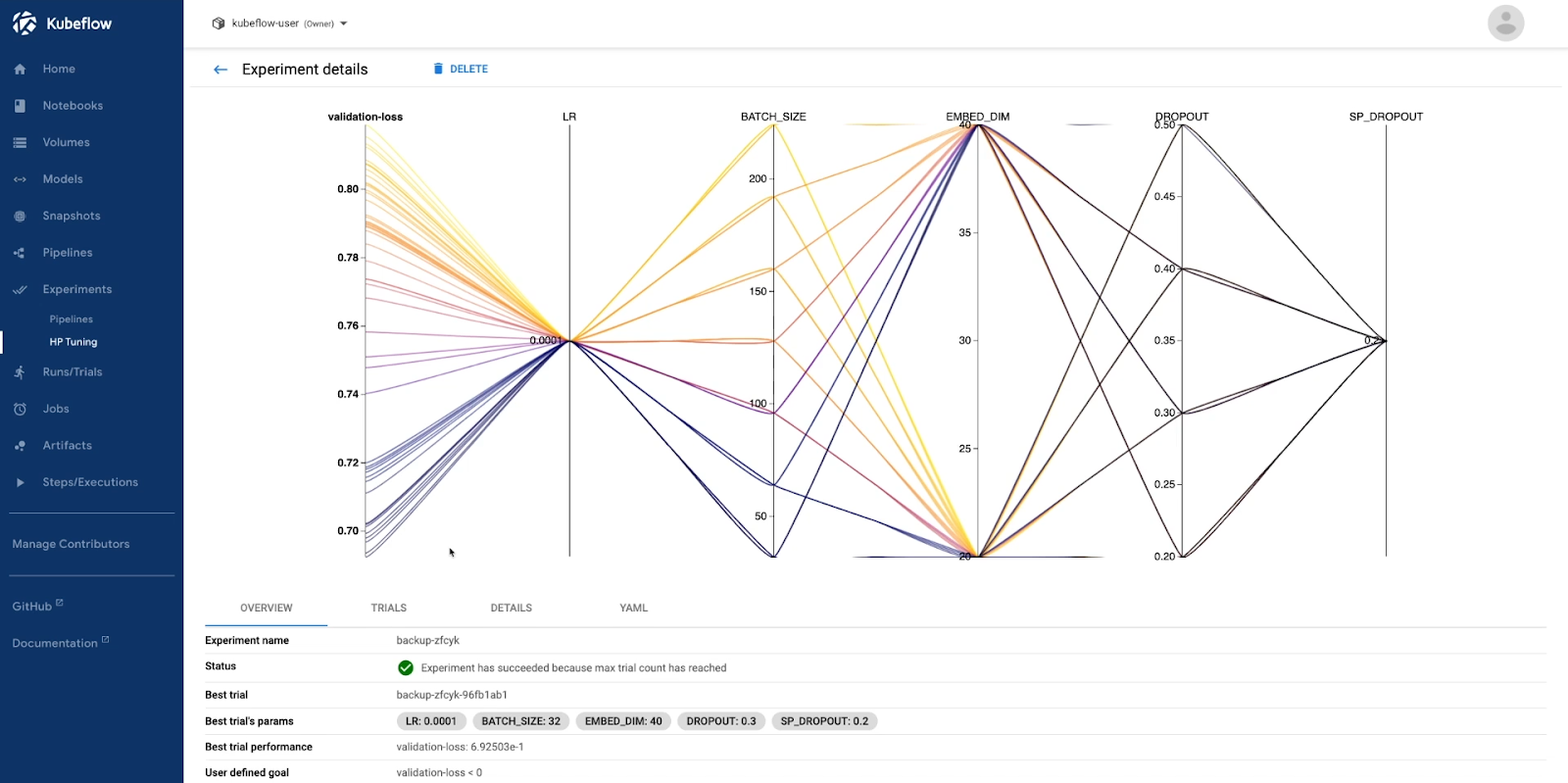
When a Katib experiment completes, all the runs and metrics are shown in Kubeflow dashboard for the data scientist to consume and infer:
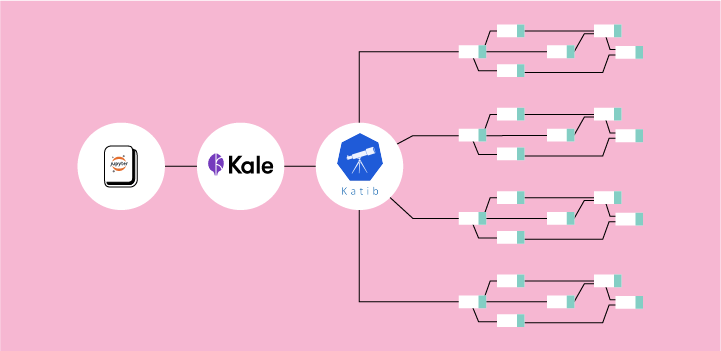
With Kale’s capability to scale up parallel runs, it is very suitable for running AutoML workflows leveraging Katib in Kubeflow. The Meta-Learning system employed by Kale will suggest some model architectures that it thinks will perform well. Kale then starts Kubeflow pipelines to train these model architectures, and collects all the results from the previous step. As soon as all pipelines are done, it retrieves the best performing one, based on the target metric and starts a new Katib HP Tuning experiment on the best models. It does this to further optimize its initialization parameters, continually log models, datasets, and TensorBoard reports to MLMD, using reproducible Rok snapshots. Kale provides a complete lineage with experiments and everything related is persisted into immutable Rok snapshots.
Kubeflow Serving
KFServing is a novel cloud-native multi-framework model serving tool for serverless inference. KFServing abstracts away the complexity of server configuration, networking, health checking, autoscaling of heterogeneous hardware (CPU, GPU, TPU), scaling from zero, and progressive (aka. canary) rollouts. It provides a complete story for production ML serving that includes prediction, pre-processing, post-processing and explainability, in a way that is compatible with various frameworks – Tensorflow, PyTorch, XGBoost, ScikitLearn, and ONNX. Using the Kale API, the serving becomes as simple as running a simple command, along with support for domain specific preprocessing steps.
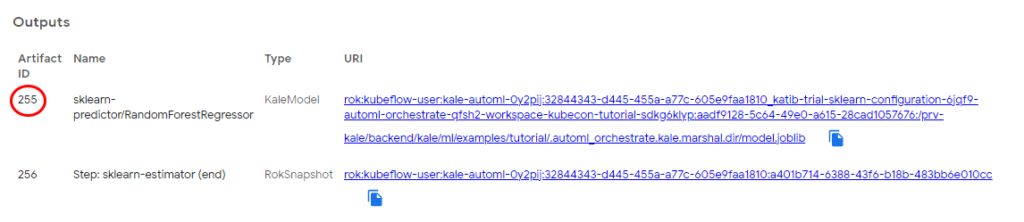

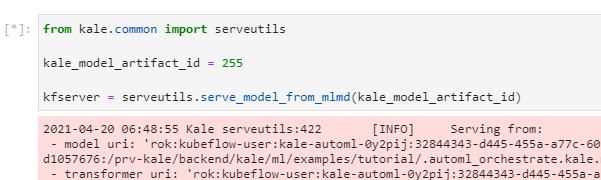
Kale recognizes the type of the model, dumps it, saves it in a specific format, then takes a Rok snapshot and creates an inference service.
From the Kubeflow dashboard, data science teams can monitor all the inference services that you deploy, see details, metrics, and logs.
From the InferenceService YAML, a canary end-point can be created and traffic will be routed using Istio to comply with specified required quotas.
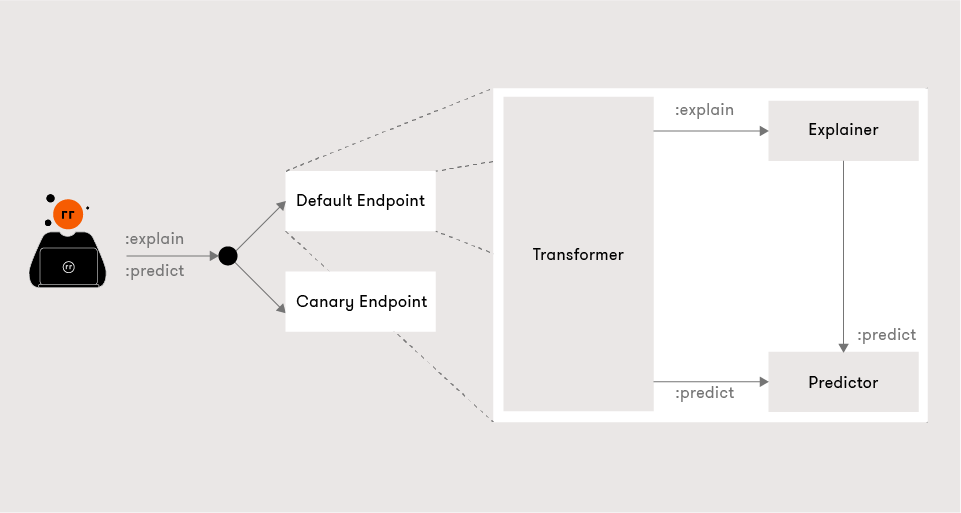
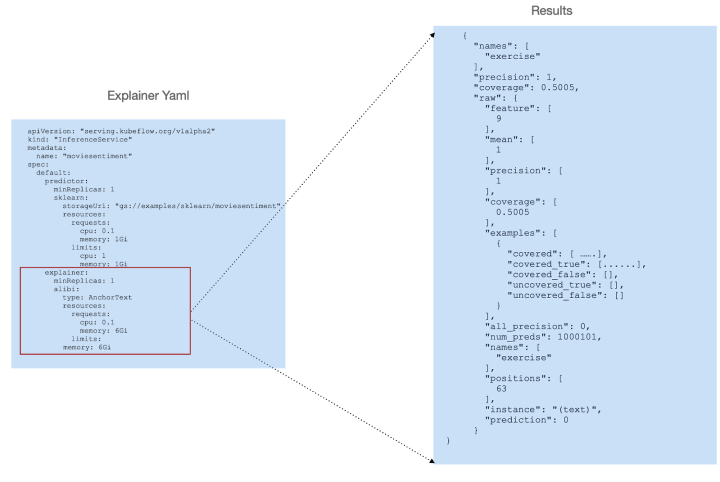
One optional feature of KFServing is the ability to add an “explainer” that enables an alternate data plane, providing model explanations in addition to predictions.
Conclusion
As we’ve shown, Kubeflow is a powerful and flexible MLOps platform. By using Kubeflow as the foundation of your MLOps platform, you can ensure the lifecycle of your ML projects is uniformly managed, experiments are reproducible, prototyping is quick and you can ship your models into production without data scientists needing deep expertise in infrastructure. We also saw how Kubeflow Pipelines enable developers to build custom ML workflows by easily “stitching” and connecting various components like building blocks using containerized implementations of ML tasks providing portability, repeatability, and encapsulation. Kubeflow makes it easy to deploy your machine learning models whether you’re running your code as notebooks or in Docker containers, Kubeflow allows you to focus on the model not the infrastructure. Kubeflow also lowers the barrier to entry by providing a visual representation of the pipeline, making it easy to understand and adopt for new users and provides an interactive UI to look at metrics and compare runs.
When Kubeflow is paired with Arrikto’s tools like Kale and Rok, data scientists can further focus on building their models and run experimentations. They don’t need to deal anymore with the heavy lifting of creating the Docker containers, building the Kubeflow pipeline, creating hyperparameter tuning experiments and deploying models. With the models deployed using Kale and Rok, it ensures the reproducibility of experiments by storing a snapshot of the data, code and all other artifacts related to a run, which can be later used to replicate an experiment.
Further Readings:
- The Winding Road to Better Machine Learning Infrastructure Through Tensorflow Extended and Kubeflow
- Kubeflow: Where Machine Learning Meets the Modern Infrastructure – The New Stack
- Harnessing the power of Machine Learning to fuel the growth of Halodoc
- Machine Learning (ML) Orchestration on Kubernetes using Kubeflow
Book a FREE Kubeflow and MLOps workshop
This FREE virtual workshop is designed with data scientists, machine learning developers, DevOps engineers and infrastructure operators in mind. The workshop covers basic and advanced topics related to Kubeflow, MiniKF, Rok, Katib and KFServing. In the workshop you’ll gain a solid understanding of how these components can work together to help you bring machine learning models to production faster. Click to schedule a workshop for your team.