

Welcome to the second blog post in our two-part series where we walk you through Kaggle’s Titanic Disaster survivor prediction notebook and convert it into a Kubeflow pipeline. In Part 1, we completed our use case with the successful run of the Kubeflow pipeline, but all the predictors had 100% scores. This is super suspicious and we have to find out what’s going wrong with the training data. In this blog post, we’re going to use Rok Snapshots to resolve the above problem!
Reproduce Prior a State from Snapshot
1. Go to randomforest step
Rok takes care of data versioning and reproducing the whole environment as it was the time you clicked the COMPILE AND RUN button. Let’s resume the state of the pipeline before training one of the models and see what is going wrong with the input data. Go to the randomforest step and click on the “Visualizations” tab.
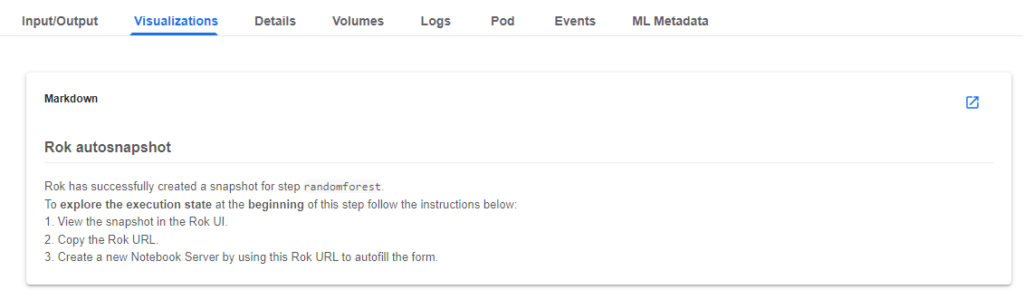
2. View the snapshot in Rok UI
Follow the steps in the Markdown. View the snapshot in the Rok UI by clicking on the corresponding link.
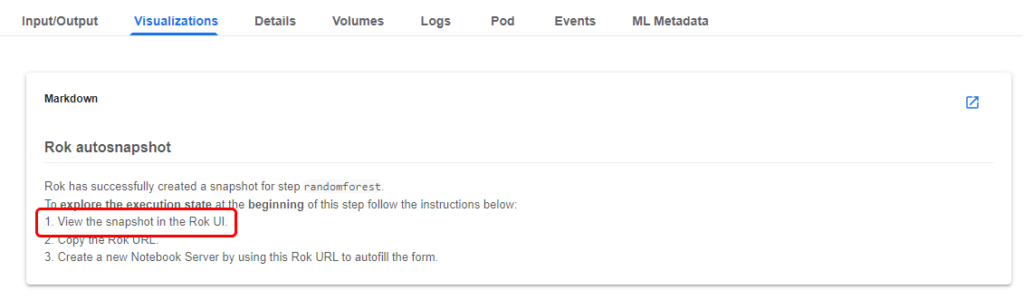
3. Copy the URL
Copy the Rok URL.
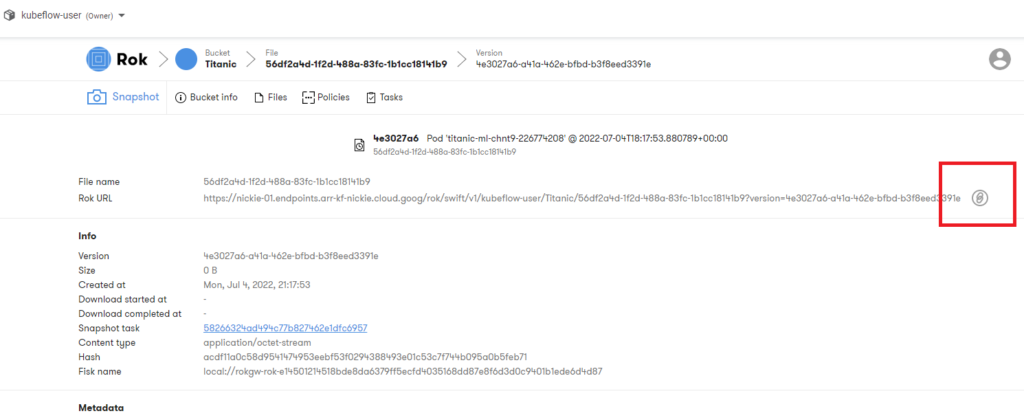
4. Navigate to the Notebooks tab and click on + New Notebook.
5. Paste the Rok URL, use the default Docker image and check the volume information.
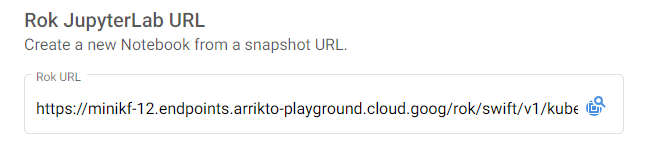

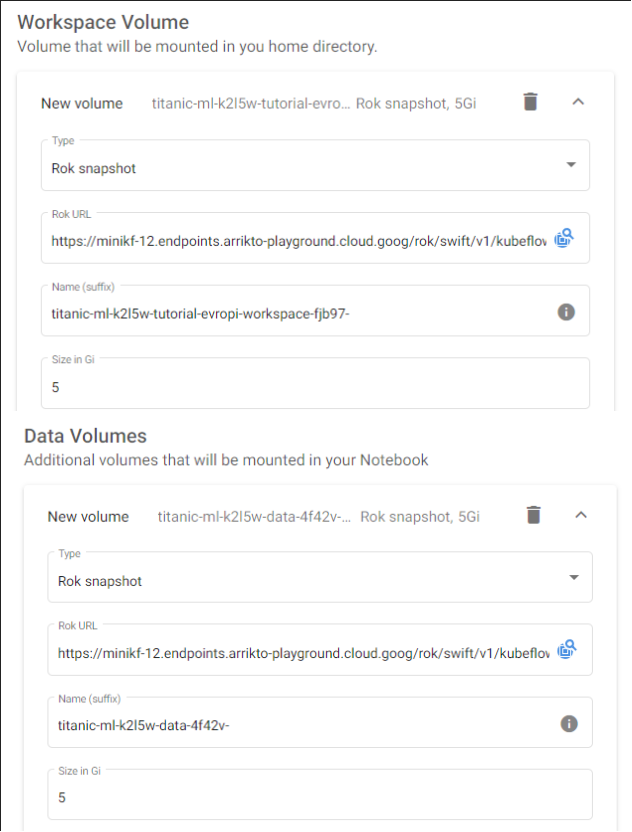
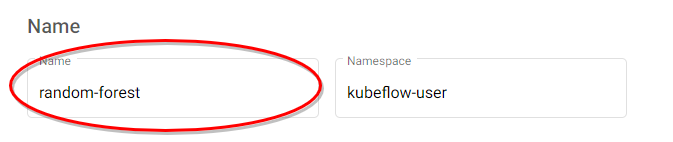
6. Name your notebook and click “Launch”.
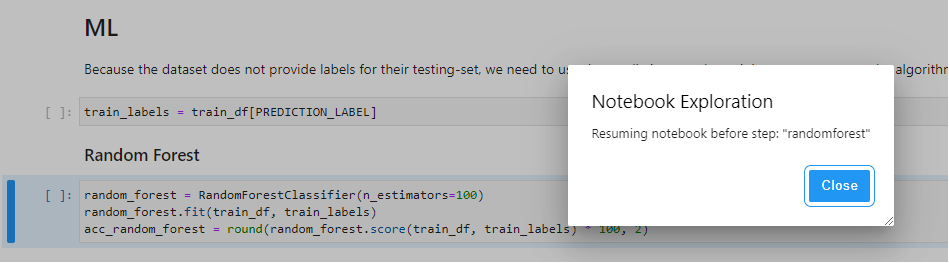
7. Connect to the Notebook. Note that the notebook opens at the exact cell of the pipeline step you have initiated.

8. Add a print command and run this cell by pressing Shift + Enter to retrain the random forest and print the score. It is 100.
print(acc_random_forest)

9. Let’s investigate if there is something strange in the training data. To see this, add a new cell with the “train_df” command above the Random Forest Markdown as it is shown below and then run it.
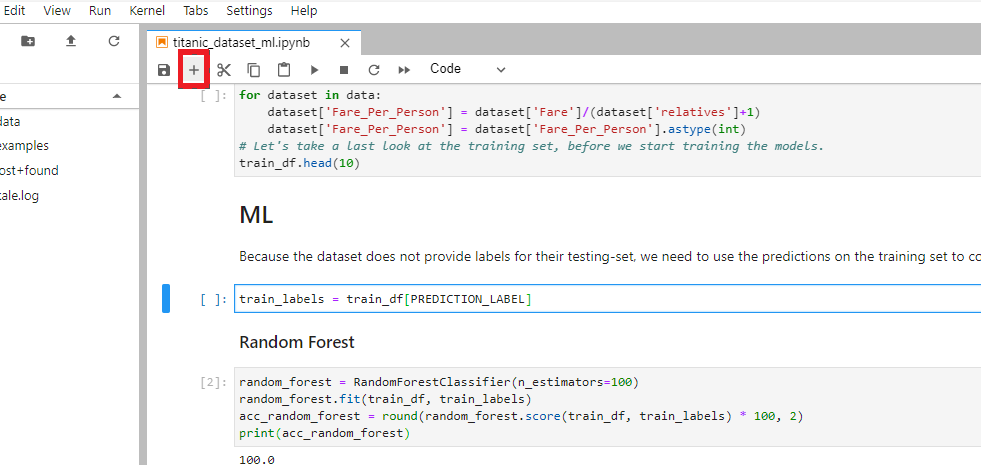
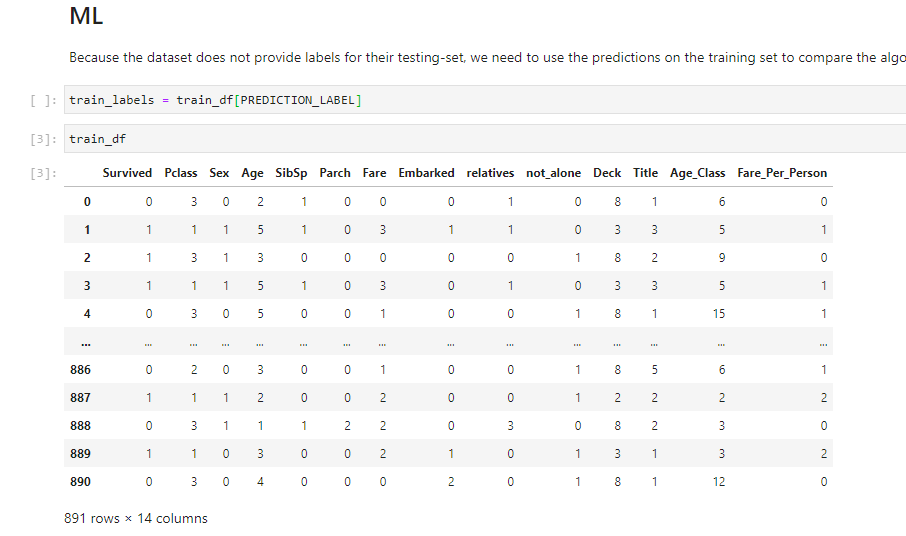
It seems that the “Survived” column has mistakenly been added to the training data. This means that the model has learned to focus on the “Survived” feature and ignore the rest. We need to remove it from the training data to let the model learn from the other features.
10. To remove this column, edit the cell to add the following command and rerun it.
train_df.drop('Survived', axis=1, inplace=True)
train_df
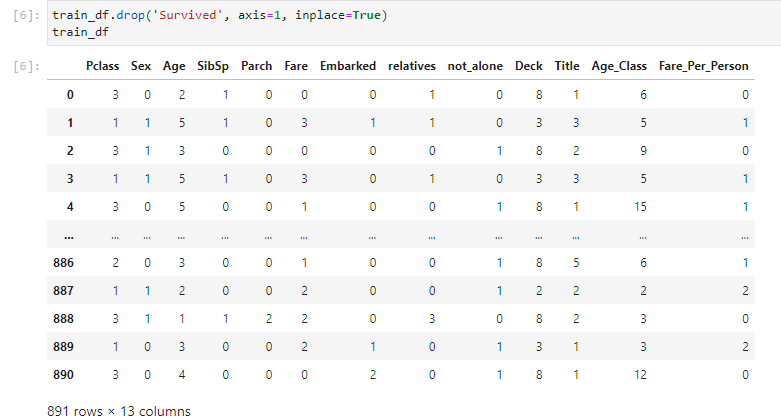
11. Enable Kale again and make sure that the cell that removes the Survived column is part of the featureengineering pipeline step. The cell will have the same outline color. Alternatively, click the pencil icon on the right side of the cell to see in which pipeline step this cell is part.

12. Run the pipeline by clicking “Compile and Run” and click to view the pipeline.
As soon as the run is complete, go to the Visualizations tab and view final results! As you see below, the scores are realistic now!
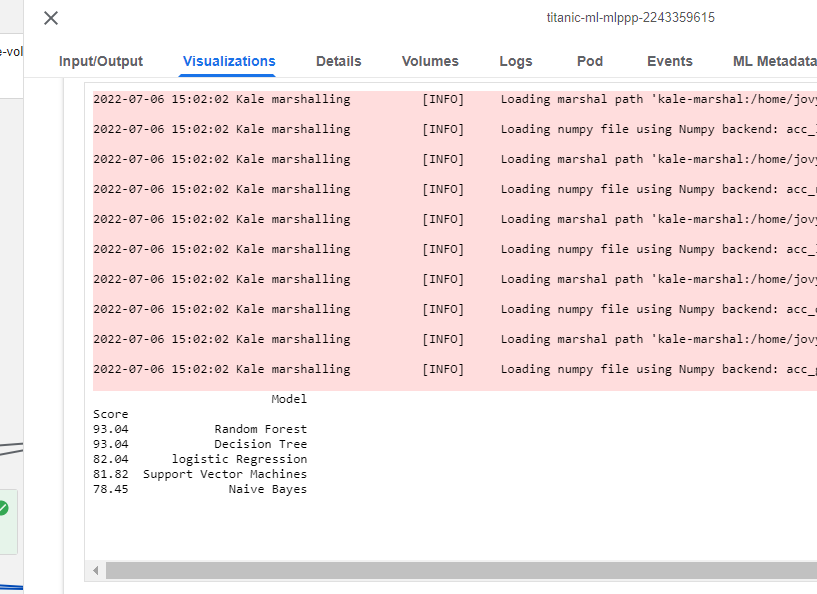
Therefore, in this blog we saw how to easily debug a code issue by adding a bugfix to the already reproduced Rok Snapshot of the Notebook.
What’s Next?
- Get started with Kubeflow in just minutes, for free. No credit card required!
- Try out the Titanic Disaster use case in Arrikto Academy.
- Try your hand at converting a Kaggle competition into a Kubeflow Pipeline
- Sign Up for an Instructor-Led Overview of the Kaggle Competition and the Notebook.
Arrikto Academy
If you are ready to put what you’ve learned into practice with hands-on labs? Then check out Arrikto Academy! On this site you’ll find a variety of FREE skills-building labs and tutorials including:
- Kubeflow Use Cases: Kaggle OpenVaccine, Kaggle Titanic Disaster, Kaggle Blue Book for Bulldozers, Dog Breed Classification, Distributed Training, Kaggle Digit Recognizer Competition
- Kubeflow Functionality – Kale, Katib
- Enterprise Kubeflow Skills – Kale SDK, Rok Registry