

Congratulations to the community of Kubeflow users, contributors, community evangelists and corporate sponsors who helped make the new Kubeflow 1.4 release possible!
What’s new in Kubeflow 1.4
The Kubeflow 1.4 release lays several important building blocks for the use of advanced metadata workflows. A quick summary of 1.4’s top deliveries includes:
- Advanced metadata workflows with improved metric visualization and pipeline step caching in Kubeflow Pipelines (KFP) via the KFP Software Development Kit (SDK)
- A new KFServing model user interface that displays ML model status, configuration, yaml, logs, and metrics
- New Optuna Suggestion Service with multivariate TPE algorithm and Sobol’s Quasirandom Sequence support for hyperparameter tuning
- A new, unified training operator that supports all deep learning frameworks with a Python SDK, enhanced monitoring and advanced scheduling support
Kubeflow 1.4 enables the use of metadata in advanced machine learning (ML) workflows, especially in the Kubeflow Pipelines SDK. With the Pipelines SDK and its new V2-compatible mode, users can create advanced ML pipelines with Python functions that use the MLMD as input/output arguments. This simplifies metrics visualization.
Another enhancement to Pipelines is the option to use the Emissary executor for non-Docker Kubernetes container runtime requirements. In addition, 1.4 can support metadata-based workflows to streamline the creation of TensorBoard visualizations and to serve ML models.
For the complete rundown on what’s new, check out the official announcement blog on Kubeflow.org.
Kubeflow Project Organization
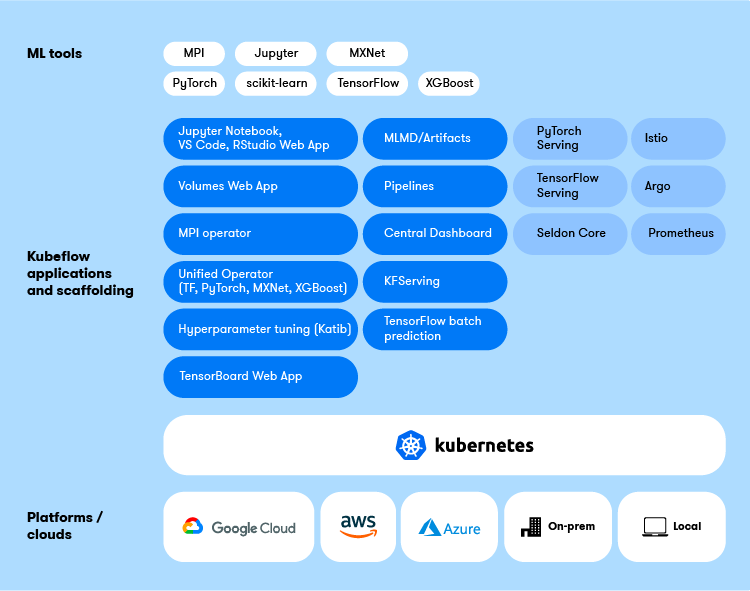
For folks not familiar with the Kubeflow project, it is made up of multiple technologies that when combined deliver a machine learning platform. For the sake of manageability, the Kubeflow project has been broken down into six working groups with associated GitHub repositories. This makes it easier to develop, document and release specific building blocks of functionality.
These working groups include:
- AutoML
- Manifests
- Notebooks
- Pipelines
- Serving
- Training
When it comes down to how Kubeflow is actually developed on GitHub, here’s the high-level view of the relevant repositories.
kubeflow/kubeflow
This main repository includes eight Kubeflow components:
- Central Dashboard – The UI that provides a jump-off point to all other facets of the platform
- Jupyter Web App – This web app is responsible for allowing the user to manipulate the Jupyter Notebooks in their Kubeflow cluster.
- Notebook Controller – The controller allows users to create a custom resource “Notebook”
- PodDefaults Webhook – Provides a way to inject common data (env vars, volumes) to pods (e.g. notebooks)
- Profiles + KFAM – Kubeflow Profile CRD is designed to solve access management within a multi-user kubernetes cluster.
- Tensorboard Controller – The controller allows users to create a custom resource for Tensorboard
- Tensorboards Web App – This web app is responsible for allowing the user to manipulate Tensorboard instances in their Kubeflow cluster.
- Volumes Web App – This web app is responsible for allowing the user to manipulate PVCs in their Kubeflow cluster.
kubeflow/kfserving (kserve)
KFServing provides a Kubernetes Custom Resource Definition for serving machine learning models on a variety of frameworks including TensorFlow, XGBoost, scikit-learn, PyTorch, and ONNX. Aside from providing a CRD, it also helps encapsulate many of the complex challenges that come with autoscaling, networking, health checking, and server configuration. In 1.4, the kubeflow/kfserving repo was moved out of the Kubeflow project and is now being developed as kserve. Read more about this change here.
kubeflow/katib
Katib (which means “secretary” in Arabic) provides automated machine learning (AutoML) in Kubeflow. Like KFServing, Katib is agnostic to machine learning frameworks. It can perform hyperparameter tuning, early stopping and neural architecture search written in a variety of languages.
kubeflow/pipelines
Kubeflow Pipelines is used for building and deploying portable, scalable machine learning workflows based on Docker containers. It consists of a UI for managing training experiments, jobs, and runs, plus an engine for scheduling multi-step ML workflows. There are also two SDKs, one that allows you to define and manipulate pipelines, while the other offers an alternative way for Notebooks to interact with the system.
kubeflow/manifests
The manifests repo periodically syncs all official Kubeflow components from their respective upstream repos. Manifests are used to install Kubeflow manually, without the aid of a prepackaged distribution.
Training Operators
In Kubeflow you train machine learning models with operators. There are currently five operators that are supported. They include:
- TensorFlow training
- PyTorch training
- MPI training
- MXNet training
- XGBoost Operator
Note that in the 1.4 release, all but the MPI training component were consolidated into a component called, “Training Operator.”
So, what’s in Kubeflow 1.4?
The table below shows the git version for each component that is included in the 1.4 release.
| Component | Upstream Revision |
| Training Operator | v1.3.0 |
| MPI Operator | v0.3.0 |
| Notebook Controller | v1.4 |
| Tensorboard Controller | v1.4 |
| Central Dashboard | v1.4 |
| Profiles + KFAM | v1.4 |
| PodDefaults Webhook | v1.4 |
| Jupyter Web App | v1.4 |
| Tensorboards Web App | v1.4 |
| Volumes Web App | v1.4 |
| Katib | v0.12.0 |
| KFServing | v0.6.1 |
| Kubeflow Pipelines | v1.7.0 |
| Kubeflow Tekton Pipelines | v1.0.0 |
Kubeflow 1.4 Contributors Summary
Ok, now that we understand how the project is organized, let’s take a look at how the contributions played out across the components surveyed. In this survey I looked at the activity in the kubeflow, manifests, pipelines, katib, kfserving and training operator repos. When all the stats of each individual repo are summed up, you end up with the following:.
- 143 total contributors by repo
- 48 unique companies (that could easily be mapped to contributors)
- 874 total commits
- 4,842 total files changed
Unique Contributors by Component
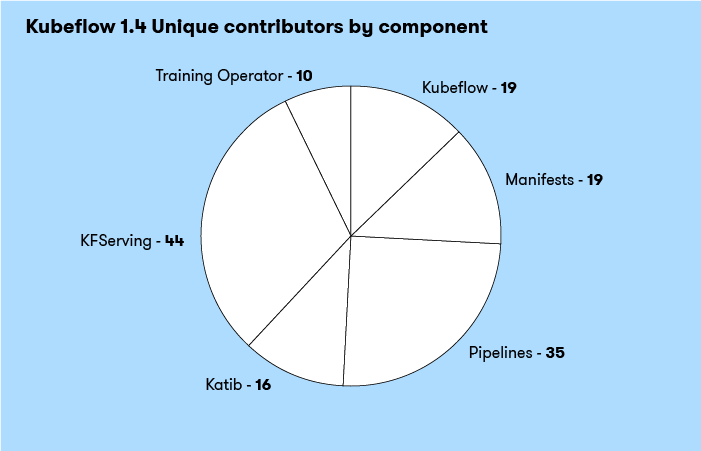
Of the six components I looked at, there were a total of 143 contributors. The component with the greatest diversity of contributors was KFServing with a total of 44.
Total Contributors by Company
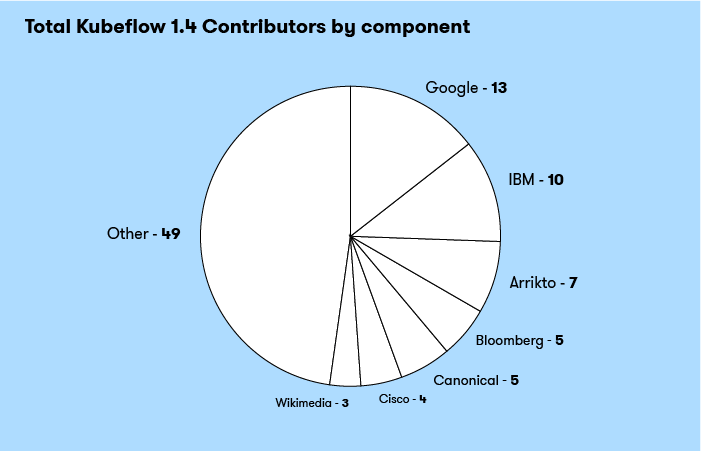
There were a total of 48 unique companies that helped contribute to the Kubeflow 1.4 release. The top five corporate contributors were:
- IBM
- Arrikto
- Bloomberg
- Canonical
Total Commits by Component
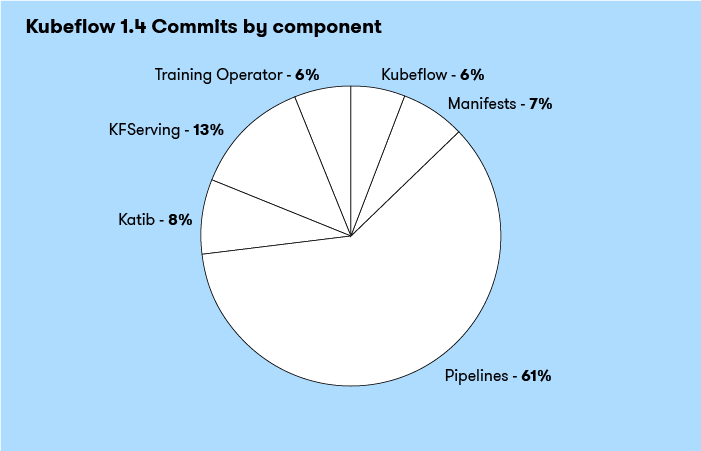
Of the six components I looked at, there were a total of 874 commits. The pipelines repo was far and away the component that saw the most commits. Roughly 5x more than the next closest component, KFServing.
Total Files Changed by Component
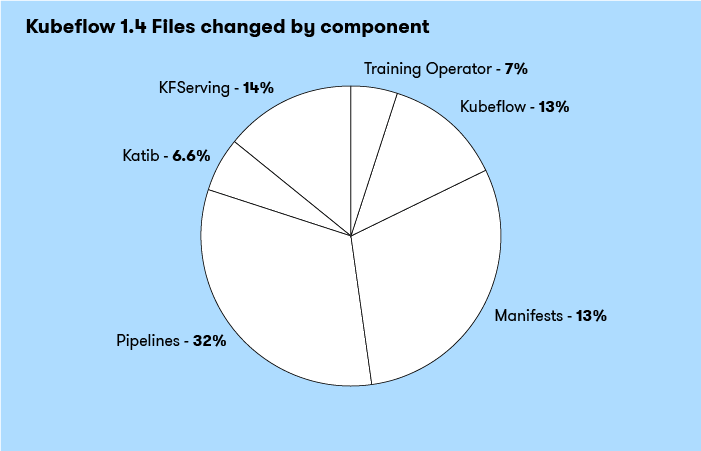
Of the six components I looked at, there were a total of 4,842 files changed. The pipelines repo again saw the most change, but not by much, the manifests component was almost equally changed in this regard.
Arrikto’s Contributions to Kubeflow 1.4
I’d like to take a moment out to give a few well deserved kudos to some of my colleagues here at Arrikto who helped make contributions to the 1.4 release:
- Kimonas Sotirchos (@kimwnasptd) – who also served as the release manager for 1.4
- Ilias Katsakioris (@elikatsis) – Especially for his ongoing work to enable ServiceAccountToken credentials to be used in Pipelines
- Yannis Zarkadas (@yanniszark)
- Josh Bottum (jbottum) – Kubeflow Community Product Manager
Drilldown: Kubeflow 1.4 Contributions by Repository
Now, let’s also dive in and take a look at the individual stats on a few select repos.
kubeflow/kubeflow
In this analysis I compared the v.1.3-branch and v1.4-branch between March 25, 2021 and Oct 6, 2021.
- 56 commits
- 544 files changes
- 19 contributors (Includes bot/automation accounts)
kubeflow/manifests
In this analysis I compared the v.1.3-branch and v1.4-branch between April 5, 2021 and Oct 6, 2021.
- 63 commits
- 1,203 files changes
- 19 contributors (Includes bot/automation accounts)
kubeflow/pipelines
In this analysis I compared 1.5.1 and 1.7.0 between July 10, 2021 and Oct 6, 2021.
- 532 commits
- 2,065 files changes
- 35 contributors (Includes bot/automation accounts)
kubeflow/katib
In this analysis I compared release-0.11 and release-0.12 between March 31, 2021 and Oct 6, 2021.
- 66 commits
- 269 files changes
- 16 contributors (Includes bot/automation accounts)
kubeflow/kfserving
In this analysis I compared release-0.5 and release-0.6 between March 4, 2021 and Oct 6, 2021.
- 109 commits
- 570 files changes
- 44 contributors (Includes bot/automation accounts)
kubeflow/training-operator
Recall that this is the first time this specific component is being included, at least under this name. In this analysis I compared the v1.2-branch and v1.3-branch between August 5, 2021 and Oct 6, 2021.
- 48 commits
- 191 files changes
- 10 contributors (Includes bot/automation accounts)
Book a FREE Kubeflow and MLOps workshop
This FREE virtual workshop is designed with data scientists, machine learning developers, DevOps engineers and infrastructure operators in mind. The workshop covers basic and advanced topics related to Kubeflow, MiniKF, Rok, Katib and KFServing. In the workshop you’ll gain a solid understanding of how these components can work together to help you bring machine learning models to production faster. Click to schedule a workshop for your team.
About Arrikto
At Arrikto, we are active members of the Kubeflow community having made significant contributions to the latest 1.4 release. Our projects/products include:
- Kubeflow as a Service is the easiest way to get started with Kubeflow in minutes! It comes with a Free 7-day trial (no credit card required).
- Enterprise Kubeflow (EKF) is a complete machine learning operations platform that simplifies, accelerates, and secures the machine learning model development life cycle with Kubeflow.
- Rok is a data management solution for Kubeflow. Rok’s built-in Kubeflow integration simplifies operations and increases performance, while enabling data versioning, packaging, and secure sharing across teams and cloud boundaries.
- Kale, a workflow tool for Kubeflow, which orchestrates all of Kubeflow’s components seamlessly.