

Hyperparameter Tuning (HP Tuning) in Machine Learning (ML) is the process of automatically choosing a set of optimal hyperparameters for a learning algorithm. But first, what do we refer to as hyperparameters? What is the difference between the model’s parameters (or weights) and the learning algorithm’s hyperparameters?
Let’s get the ML jargon out of the way first:
- Parameters: The values of the model that are updated through training (i.e., the model’s weights)
- Hyperparameters: The values of the learning algorithm that the Data Scientist explicitly sets (e.g., the learning rate, the number of hidden layers in a neural network architecture, the batch size, etc.)
From this definition, we deduce that Data Scientists are responsible for choosing the set of hyperparameters for a learning algorithm. There are two ways to go about this: one could approach this problem using their experience and setting the hyperparameters manually. On the other hand, they could also write a script that launches different training jobs to test multiple sets of hyperparameters, following popular techniques, such as grid or random search. The latter is known as HP Tuning.
Before we talk about how we can automate this process, let’s discuss where we will be automating the process from–our Jupyter Notebook (also referenced as “Notebooks”). Jupyter Notebook is a web application for creating and sharing computational documents. It offers users a simple, streamlined, document-centric experience. Find out more about the Kubeflow Project’s use of Jupyter Notebooks and the Notebook Working Group on the Kubeflow website.
Now, we can discuss how we can automate this process from our Jupyter Notebook without changing a single line of code. Writing boilerplate code to fine-tune the model should be separate from the learning process. We should refrain from polluting our Notebooks with cells tasked with this job to keep the document focused on the modeling process.
This article shows how Katib can handle HP Tuning using state-of-the-art techniques, like Bayesian Optimization, and how Kale flattens the learning curve, so a Data Scientist can create Katib experiments without knowing its internals.
From Jupyter Notebooks to HP Tuning
Having set the stage, let us see how we transition from a Jupyter Notebook, whose purpose is to experiment with a learning algorithm, to an HP Tuning job, which tries to find the optimal set of the learning algorithm’s hyperparameters. The goal is to do this without writing a single line of code or altering our habits.
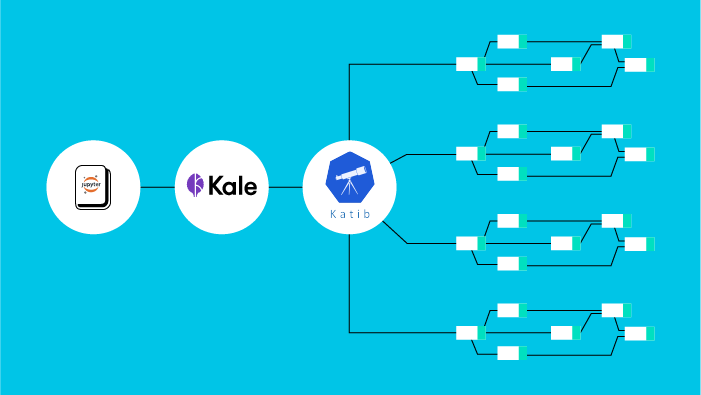
To this end, we use a component of Kubeflow called Katib. Katib is a Kubernetes-based system for HP Tuning and Neural Architecture Search. Katib is agnostic to ML frameworks, but it also integrates with the Kubeflow Training Operator to launch distributed training jobs for frameworks like TensorFlow or PyTorch.
For this example, we will use the Dog Breed tutorial and Kale. Kale is an open-source project aiming to simplify the orchestration of ML operations on Kubeflow. You can use Kale to convert a Jupyter Notebook to a Kubeflow Pipeline, launch distributed training jobs, or serve your models. In this article, we’ll run a Katib experiment from our Notebook environment.
In this article, we follow a different approach. Instead of showing you how to set up a working environment first, we dive directly into the task. So, let’s see how simple it is to create an HP Tuning experiment from a Jupyter environment using Kale and Katib.
Assuming we have a Notebook kernel running, all we have to do is open Kale from the left side panel, enable it, and set up a Katib job.
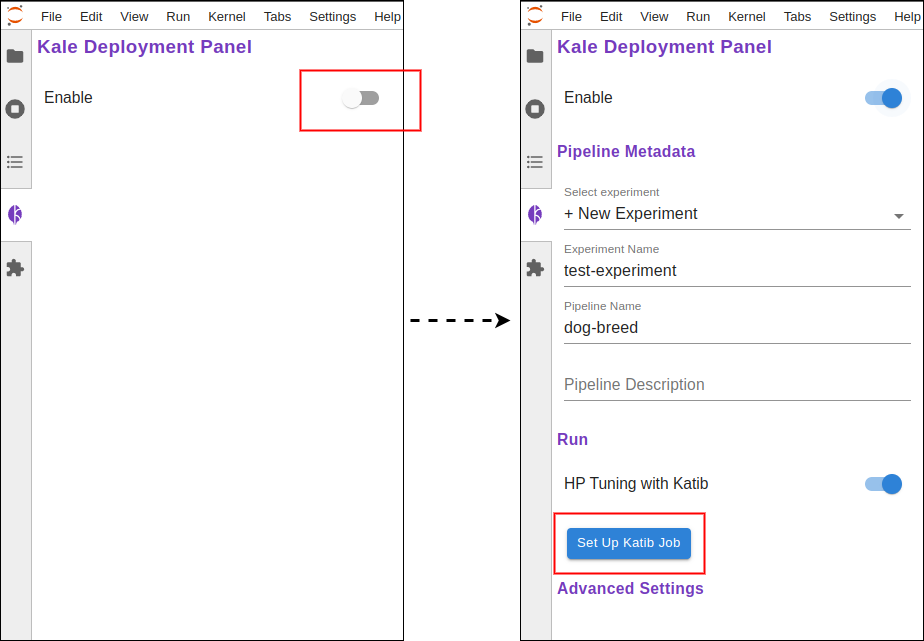
Moreover, we see that, when enabled, Kale annotates the cells of the Notebook. Each annotation is a step in the ML Pipeline. You can play around and create your steps, but don’t forget to set the dependencies of each cell.
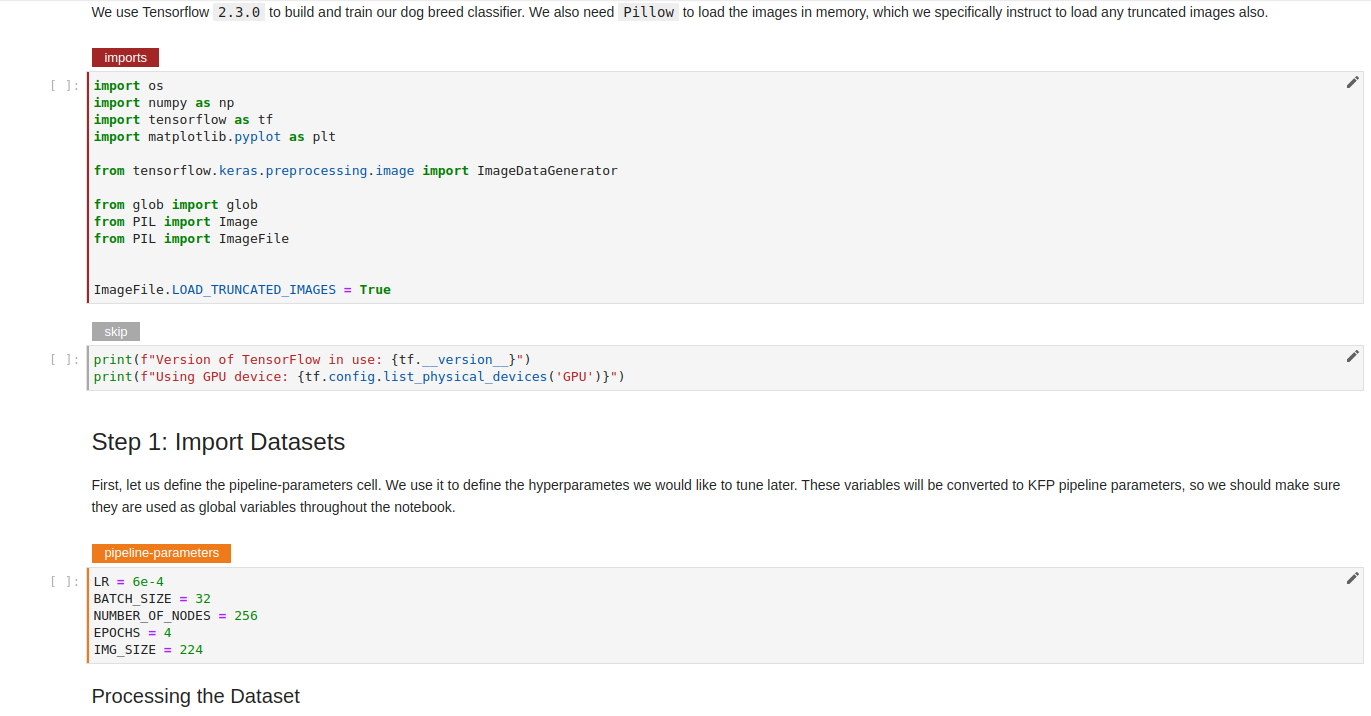
In any case, the annotations that we care about are the following:
- The
pipeline-parameterscell, which defines the hyperparameters in this Notebook. - The
pipeline-metricscell at the end of the notebook; this cell defines the metric that we try to optimize by changing the hyperparameters.
The Kale UI will pick up the hyperparameters automatically from the `pipeline-parameters` cell. We have to choose the values we want to try for each parameter by providing a list of items or a valid range. Also, we should select the optimization algorithm and the metric we want to optimize.
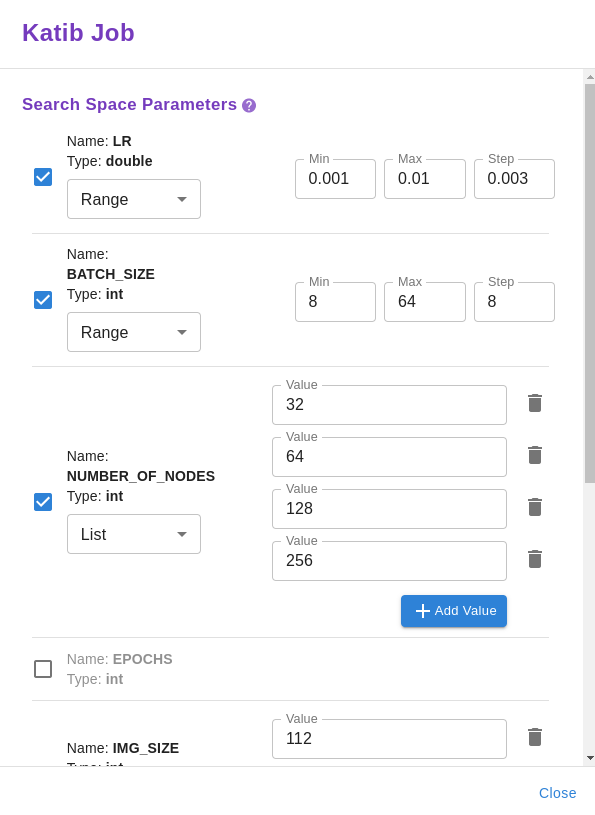
After pressing the COMPILE AND RUN KATIB JOB button on the bottom, we can follow the link to watch the experiment live or wait to get the results via the Kale user interface. This is what the Katib experiment looks like in the end.
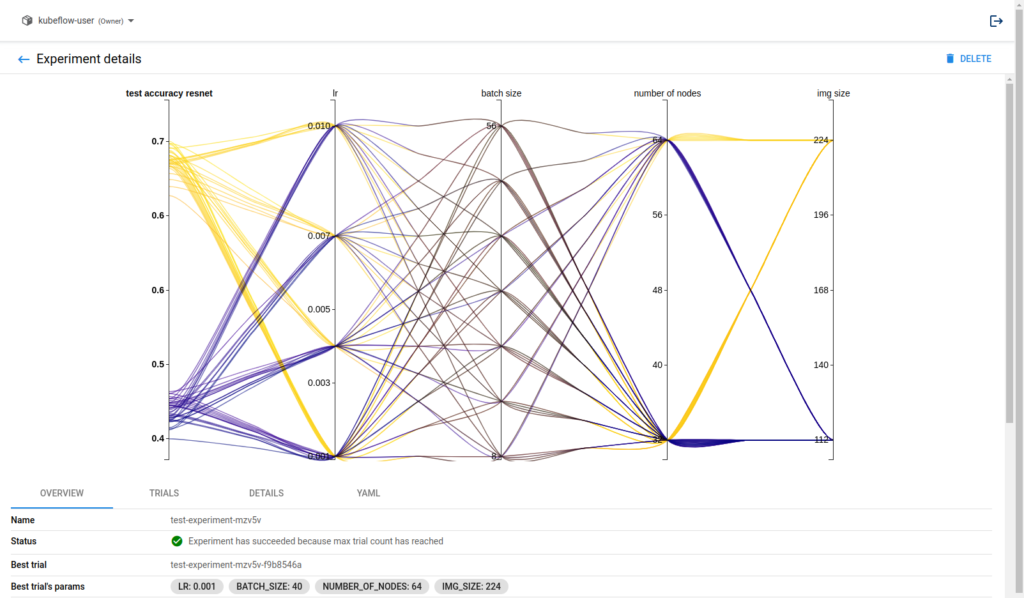
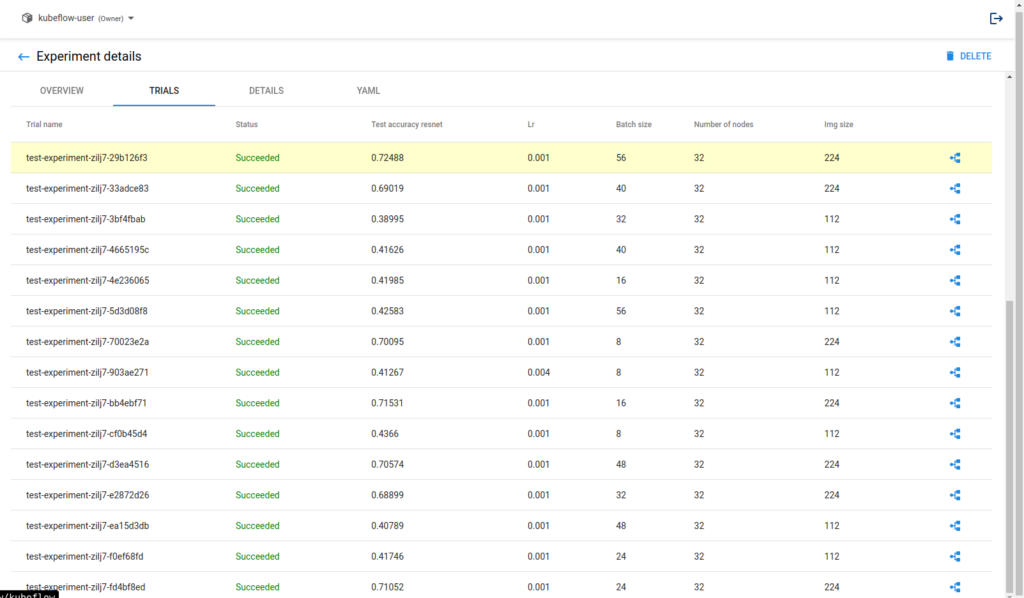
Katib will retrieve the best hyperparameter combination for our model. You can find the best combination highlighted in the trials tab. This is as easy as it gets!
How Can I Get All That?
Now, let’s see how to set up our environment. To get an instance of Kubeflow running, we will use Kubeflow as a Service. Kubeflow as a Service is the easiest way to get started with Kubeflow!
- Point and click Kubeflow deployment.
- Free 7-day trial, no credit card required.
- 8 vCPUs, 30 GB RAM, 700 GB disk.
Head to kubeflow.arrikto.com and sign up to create your first Kubeflow deployment.
Running a Jupyter Server
Now, we need a Jupyter Notebook instance. Creating a Jupyter Notebook is easy in Kubeflow as a Service, using the provided Jupyter Web App:
- Choose
Notebooksfrom the left panel. - Click the
New Serverbutton. - Fill in a name for the server and optionally request the amount of
CPUandRAMyou need and clickLAUNCH.
To follow this tutorial, we’ll use the default Kale image, so you don’t have to configure it further.
After completing these three steps, wait for the Notebook Server to get ready and connect by clicking the Connect button. You’ll be transferred to your familiar JupyterLab workspace.
Get the code
To get the example of the story, create a new terminal in the JupyterLab environment and clone the following repo:
git clone https://github.com/arrikto/examplesYou can find the Dog Breed example in “examples > academy > dog-breed-classification/dog-breed-v2.ipynb”.
Conclusion
This article shows how to decouple our model training pipelines from the HP Tuning process. We also demonstrated using Kubeflow as a Service to create a single-node Kubeflow instance.
Then, we turned to Kale and Katib to automate the process of running HP Tuning experiments from a Jupyter Notebook.
We are now ready to let Katib handle HP Tuning for us and use state-of-the-art techniques, like Bayesian Optimization and Neural Architecture Search (NAS).
Helpful Links and More information
Learn more about the Kubeflow Project and how to get involved
