

GPUs are essential for accelerating Machine Learning workloads comprising throughput-intensive model training, latency-sensitive inference, and interactive development, usually done in Jupyter Notebooks (https://jupyter.org/). A common practice is deploying ML jobs as containers managed by Kubernetes (https://kubernetes.io/).
Kubernetes schedules GPU workloads by assigning a whole device to a single job exclusively. This one-to-one relationship leads to massive GPU underutilization, especially for interactive jobs, characterized by significant idle periods and infrequent bursts of heavy GPU usage. Current solutions enable GPU sharing by statically assigning a fixed slice of GPU memory to each co-located job. These solutions are not suitable for interactive scenarios since the number of co-located jobs is limited by the size of physical GPU memory. Consequently, users must know the GPU memory demand of their jobs before submitting them for execution, which is impractical.
1. GPUs and Kubernetes
NVIDIA is by far the most prevalent GPU vendor when it comes to general-purpose GPU computing. Google Cloud Platform (https://cloud.google.com/compute/docs/gpus) and Amazon Web Services (https://aws.amazon.com/ec2/instance-types/) almost exclusively offer NVIDIA GPUs.
The de facto way of handling GPUs in a Kubernetes cluster is via NVIDIA’s Device Plugin [1].
For a Kubernetes node with N physical GPUs, the device plugin advertises N `nvidia.com/gpu` devices to the cluster.
While containers can request fractional amounts of CPU and memory, they can only request GPUs in integer numbers.
Thus, Kubernetes enforces a 1-1 assignment between GPUs and containers. Even if a container does minimal work on a GPU throughout its lifetime, that GPU is unavailable to the rest of the cluster while the container is running.
[1] : https://github.com/NVIDIA/k8s-device-plugin/
2. GPU Usage Patterns (Focus on the ML Case)
Let’s examine Machine Learning as a use-case for GPU acceleration.
Linear algebra operations are the core of ML computations. GPUs are massively parallel by nature, and can perform many of these straightforward linear algebra operations simultaneously. Machine learning needs to handle huge amounts of data. Thus the high memory bandwidth of GPUs is utilized to speed up the ML development process.
Machine Learning jobs in K8s usually fall in these three buckets:
- Training
- Inference
- interactive Development/experimentation
In inference jobs requests arrive in a random manner. There are significant idle periods and therefore limited GPU utilization.
ML practitioners usually develop on Jupyter Notebooks. Jupyter Notebooks are long-running interactive processes that provide an excellent environment for experimentation, which involves iterating over code, making changes, and recalibrating a model until the result is adequate.
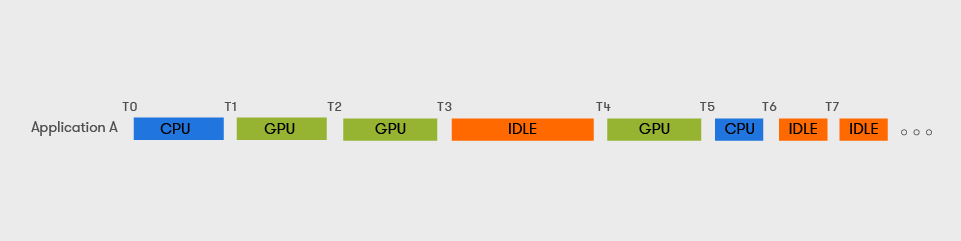
ML Development Tasks (Notebooks)
- do not perform a predetermined amount of work ; their execution times cannot be calculated/bound.
- are long-running tasks with GPU usage patterns that are characterized by bursts and generally have large idle periods (during code refactoring/debugging/developer breaks)
3. The Problem (Why the 1-1 Binding is a Bad Idea)
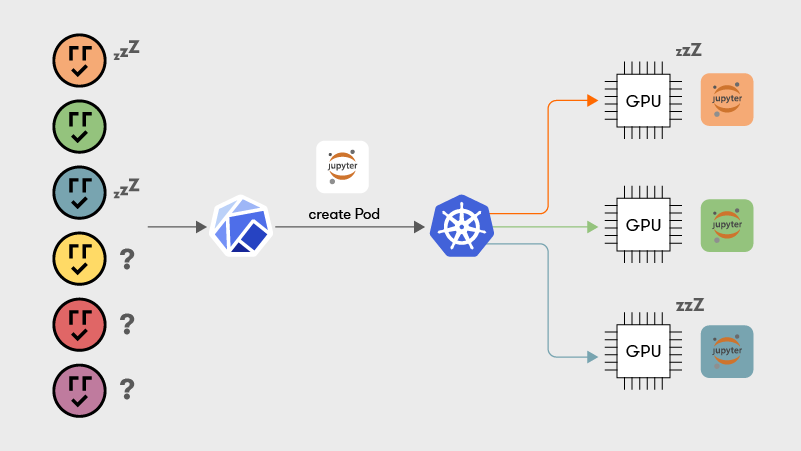
GPUs are underutilized; there is no option to co-locate tasks (Kubernetes containers) on the same GPU, resulting in incredibly wasteful utilization for tasks with intermittent GPU bursts, such as interactive ML development or inference.
Here are some instances of users voicing the problem:
- “GPUs cannot be shared – GPUs must be shared” from the Jupyter forums [2]
- “Is sharing GPU to multiple containers feasible?” Github Issue on the Kubernetes repository [3]
[2]: https://discourse.jupyter.org/t/gpus-can-not-be-shared-but-gpus-must-be-shared/1348/7
[3]: https://github.com/kubernetes/kubernetes/issues/52757
4. Why did NVIDIA choose a 1-1 binding? (or The Root of the Problem)
Let’s imagine a scenario where this 1-1 binding didn’t hold.
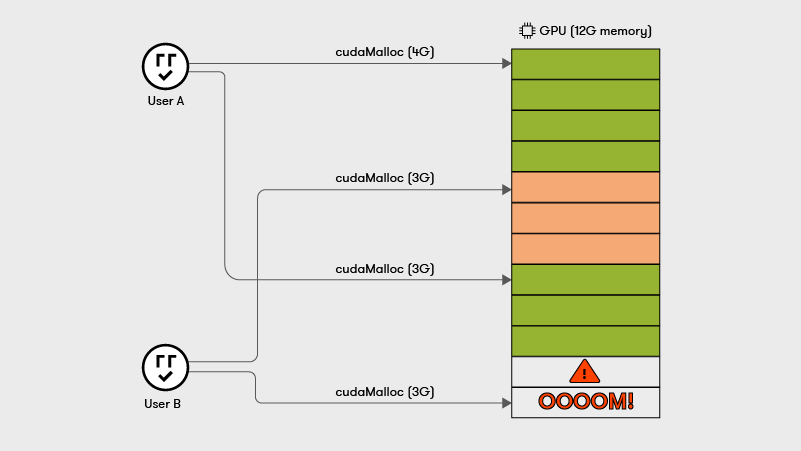
Processes using the same GPU compete for the same pool of physical GPU memory for their allocations. Each byte that a process allocates must be backed by a byte in physical GPU memory. Therefore, the sum of memory allocations across all processes using a GPU is capped by the GPU’s physical memory capacity.
Since processes can grow and shrink their GPU memory usage dynamically and the allocation requests are handled in a FIFO (First in First out) order, there can be scenarios where processes fail with Out-of-Memory (OOM) errors.
While a process cannot interfere with the GPU memory contents of another as each process owns a distinct page table, NVIDIA provides no way to restrict how much GPU memory each process allocates.
This looming danger of a hard OOM error for any colocated GPU process is why Nvidia opted for a 1-1 GPU-container binding for their Kubernetes device plugin.
5. The real challenge of GPU virtualization on K8s
While the problem of exclusive assignment of GPUs can be solved trivially (for example by modifying the upstream device-plugin to advertise a greater number of `nvidia.com/gpu` than physical GPUs) the core issue is that of managing the friction between collocated tasks, i.e., how 2 or more processes on the same node behave, irrespective of Kubernetes, see paragraph (4) and that is hard to solve.
Consequently, any complete solution must comprise:
- a mechanism to isolate the GPU usage between processes on the same node and facilitate sharing
- a K8s-specific way of exposing that mechanism via custom resources, request formatting, to the users of the cluster. In one word, a K8s integration.
We should also clarify that at any given moment only one container (a context in CUDA terms) can actively use a GPU’s computational units. The GPU driver and hardware handle context switching in an undisclosed manner. This span of time for which a container exclusively computes on the GPU is in the order of magnitude of a few milliseconds.
6. Existing approaches to GPU virtualization and sharing
We have identified GPU memory as the key blocking factor for interprocess GPU sharing.
The teams behind GPU sharing solutions have also identified this as a blocking factor.
Since we’re talking about Kubernetes, all of the existing GPU sharing approaches we’ll mention are integrated with it, i.e., they offer a way for users to consume a shared GPU device in the same way they would with an `nvidia.com/gpu` (the default way).
Therefore, we can classify existing GPU sharing solutions into the following categories, based on the way they choose to tackle the memory issue:
A. Solutions that ignore the memory issue
These approaches simply advertise multiple replicas of the same GPU to the Kubernetes cluster, but take no measure to limit the GPU memory usage of each container.
They warn users that they must “take appropriate measures” to ensure that the sum of GPU memory usage does not exceed physical GPU memory and leave it up to them to avoid OOM errors.
Such notable approaches are:
- Time-sharing GPUs on GKE
(https://cloud.google.com/kubernetes-engine/docs/concepts/timesharing-gpus)
As the documentation states, users must themselves enforce application-specific GPU memory limits:
“GKE enforces memory (address space) isolation, performance isolation, and fault isolation between containers that share a physical GPU. However, memory limits aren’t enforced on time-shared GPUs. To avoid running into out-of-memory (OOM) issues, set GPU memory limits in your applications.”
- NVIDIA Device Plugin CUDA time-slicing
(https://github.com/NVIDIA/k8s-device-plugin#shared-access-to-gpus-with-cuda-time-slicing)
This approach oversubscribes a GPU device by running multiple applications under the same CUDA context, which is the equivalent of a CPU process. The downside is that this nullifies the CUDA memory and error isolation guarantees.
Quoting the docs:
“However, nothing special is done to isolate workloads that are granted replicas from the same underlying GPU, and each workload has access to the GPU memory and runs in the same fault-domain as of all the others (meaning if one workload crashes, they all do).”
B. Solutions that tackle the memory issue to some extent
We can further classify these into:
B1. Those that implement GPU memory slicing without an enforcement mechanism:
Aliyun GPU Sharing Scheduler Extender
(https://github.com/AliyunContainerService/gpushare-scheduler-extender)
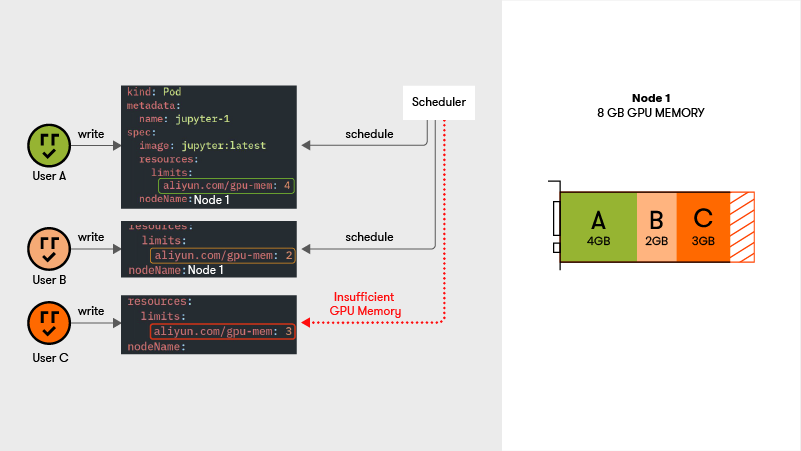
This approach uses a custom device plugin which advertises the resource `aliyun.com/gpu-mem` to the cluster. Instead of requesting integer GPU quantities, containers now request MiBs of GPU memory, and Kubernetes bin packs containers based on their GPU memory requests.
However, this approach does not enforce this GPU memory slicing in action, and instead leaves it up to the users to do so, same as the approaches in section (A).
OOM errors can still happen for any container sharing the GPU.
B2. Those that enforce GPU memory slicing during runtime
These approaches follow a similar approach to the ones in B1 regarding Kubernetes scheduling, i.e. they use GPU memory for bin packing.
Kubeshare
(https://github.com/NTHU-LSALAB/KubeShare)
This approach not only uses GPU memory to schedule container requests, but it also enforces these requests in action. For example, a container that has requested 500 MiB can at most allocate that amount of GPU memory at runtime. If it tries to allocate more, it will fail with an OOM error.
Kubeshare achieves this by hooking the CUDA API memory allocation calls and ensuring a container cannot allocate more memory than it has requested from Kubernetes.
TKEStack GPU Manager
(https://github.com/tkestack/gpu-manager)
This approach is very similar to Kubeshare. It schedules containers based on their GPU memory requests, enforcing them at runtime.
7. Shortcomings of existing approaches
Hard limit on memory
All of the existing approaches impose a hard limit on GPU memory that users must specify when submitting their workload. It is usually impossible to know the peak memory usage of a job beforehand, especially when an interactive development job is concerned. This hard limit restricts the flexibility of the user’s workflow with regard to testing out incrementally larger models. They will either have to request a large amount of memory that will mostly remain unused, or potentially face an OOM error.
Number of co-located processes limited by physical GPU memory
As we mentioned, for normal CUDA memory allocations, the sum of them across all processes must be smaller than physical GPU memory capacity. As a result, under all existing schemes, the number of processes that can be co-located is limited by this memory capacity. There is no option to oversubscribe GPU memory.
8. Assessing the current state of the art
Assignment is no longer exclusive between Pods and GPUs, the new resource that K8s uses for bin packing is GPU memory.
These existing GPU sharing approaches are suitable for ML inference, since GPU memory size is predictable.
However, this new criterion, coupled with the nature of workloads with infrequent GPU bursts (such as interactive ML model exploration on Jupyter Notebooks) still allows for underutilization scenarios.
Let’s imagine a scenario in which a GPU has 4 GB of memory and a user first submits job A with a 2.5 GB memory request while another user submits job B with a 2 GB request.
Job B will never be scheduled while job A is running, regardless of job A’s actual memory usage. This is acceptable in cases of computationally intensive tasks (ML training), however for interactive tasks the GPU remains underutilized throughout job A’s non determinable duration.
Arrikto is committed to pushing forward the state of the art in GPU virtualization on Kubernetes and assisting ML practitioners and enterprises in optimizing their compute and Cloud costs. Kiwi (https://docs.arrikto.com/release-2.0/features/kiwi.html), Arrikto’s GPU Sharing feature, is available as a technical preview in EKF 2.0. We will discuss how we engineered Kiwi to solve the aforementioned limitations in a future blog post – stay tuned!
Appendix
ML Frameworks’ handling of GPU Memory
ML frameworks prefer to handle GPU memory through internal sub-allocators. As such, they request GPU memory in large chunks and usually overshoot real “demand”. Additionally, Tensorflow [4] by default allocates all GPU memory. This behavior can be optionally altered in order to allow GPU memory usage to grow as needed. Still that usage will never shrink. If an ML job’s “actual” need fluctuates from 500MiB to 2.5 GiB, then back to 500MiB, then the allocated GPU memory will be 2.5 GiB until the TF process terminates.
[4]: https://www.tensorflow.org/guide/gpu#limiting_gpu_memory_growth
